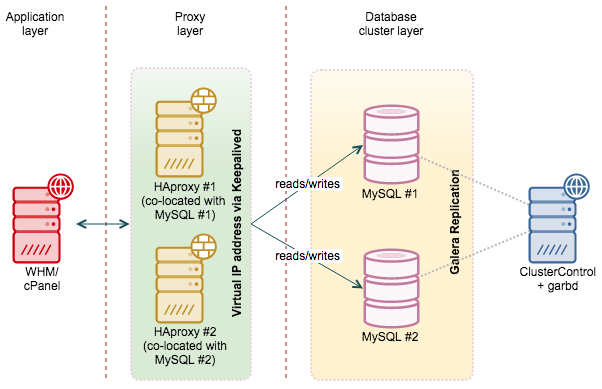
When it comes to the query tuning, EXPLAIN is one the most important tool in the DBA’s arsenal. Why is a given query slow, what does the execution plan look like, how will JOINs be processed, is the query using the correct indexes, or is it creating a temporary table? In this blog post, we’ll look at the EXPLAIN command and see how it can help us answer these questions.
![]()
This is the thirteenth installment in the ‘Become a MySQL DBA’ blog series. Our previous posts in the DBA series include Database Indexing, Deep Dive pt-query-digest, Analyzing SQL Workload with pt-query-digest, Query Tuning Process, Configuration Tuning, Live Migration using MySQL Replication, Database Upgrades, Replication Topology Changes, Schema Changes, High Availability, Backup & Restore, Monitoring & Trending.
Simple query EXPLAINed
We’d like to start with a simple example of EXPLAIN statement to get an understanding of the kind of data it provides us with. Let’s take a look at this simple query to the ‘Sakila’ database:
mysql> EXPLAIN SELECT inventory_id, customer_id FROM rental WHERE rental_date='2005-05-24 22:53:30'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: rental
type: ref
possible_keys: rental_date
key: rental_date
key_len: 5
ref: const
rows: 1
Extra: Using index
1 row in set (0.00 sec)
We have a simple query to the ‘rental’ table which should return some information about rentals that happened at a given point in time. ‘select_type’ is SIMPLE which means this is not a UNION nor subquery. Next bit of the information is the table which is queried - ‘rental’ table, as expected. Next column, ‘type’, this is an information about join type. It’s more like an info about how rows will be accessed. In our case it’s ‘ref’, which means that it can be multiple matching rows and access will be done through an index.
There are multiple join types and you can find detailed information about them in the MySQL documentation, we’d still like to mention some of the most popular ones.
eq_ref- rows will be accessed using an index, one row is read from the table for each combination of rows from the previous tables. This basically means that we are talking about UNIQUE or PRIMARY keys.
ref- as discussed, multiple rows can be accessed for a given value so we are using standard, non-unique index to retrieve them.
index_merge - rows are accessed through the index merge algorithm. Multiple indexes are used to locate matching rows. This is actually the only case where MySQL can utilize multiple indexes per query.
range - only rows from a given range are being accessed, index is used to select them.
index - full index scan is performed. It can be either a result of the use of a covering index or an index can be used to retrieve rows in a sorted order.
ALL - full table scan is performed
The next two columns in the EXPLAIN output, ‘possible_keys’ and ‘key’ tells us about indexes which could be used for the particular query and the index chosen by the optimizer as the most efficient one.
‘key_len’ tells about the length of the index (or a prefix of an index) that was chosen to be used in the query.
‘ref’ column tells us which columns or constants are compared to the index picked by the optimizer. In our case this is ‘const’ as we are using a constant in the WHERE clause. This can be another column, for example in the case of a join. You can also see ‘func’ when we are comparing a result of some function.
‘rows’ gives us an estimate of how many rows the query will scan, this estimate is based on the index statistics from the storage engine therefore it may not be precise. Most of the time, though, it’s good enough to give a DBA some insight into how heavy the query is.
Final column, ‘Extra’, prints additional information relevant to how the query is going to be executed. You can see here information about different optimizations that will be applied to the query (using MRR, or index for group by or many others), information if a temporary table is going to be created and lots of other data. More information in the MySQL documentation so we encourage you to have this page somewhere near and refer to it when you’ll see something not clear in the EXPLAIN output.
In our case we can see ‘Using index’ which means that a covering index has been used for this query. It was possible because ‘rental_date’ index definition covers all the columns involved in our query:
UNIQUE KEY `rental_date` (`rental_date`,`inventory_id`,`customer_id`),
JOINs
Let’s see what the EXPLAIN output of more complex query looks like. We’ll try to find all films released in the year of 2006 where the actor with a last name of ‘MIRINDA’ starred.
mysql> EXPLAIN SELECT title, description FROM film AS f JOIN film_actor AS fa ON f.film_id = fa.film_id JOIN actor AS a ON fa.actor_id = a.actor_id WHERE a.last_name = 'MIRANDA' AND f.release_year = 2006\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: a
type: ref
possible_keys: PRIMARY,idx_actor_last_name
key: idx_actor_last_name
key_len: 137
ref: const
rows: 1
Extra: Using where; Using index
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: fa
type: ref
possible_keys: PRIMARY,idx_fk_film_id
key: PRIMARY
key_len: 2
ref: sakila.a.actor_id
rows: 13
Extra: Using index
*************************** 3. row ***************************
id: 1
select_type: SIMPLE
table: f
type: eq_ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 2
ref: sakila.fa.film_id
rows: 1
Extra: Using where
3 rows in set (0.00 sec)
Output is longer, we can see that three tables are involved in the query. As you can see, EXPLAIN refers to them using aliases defined in a query.
By looking at the output we can see that the optimizer decided to start with the ‘actor’ table, using ‘idx_actor_last_name’ index to search for the correct last name. As a next step, ‘film_actor’ table was joined. PK was used to identify rows and as a reference sakila.a.actor_id column was used. Finally, ‘film’ table was joined, again using primary key. As you can see, join type was ‘eq_ref’ which means that for every row in the ‘film_actor’ table, only a single row in the ‘film’ table was queried.
By looking at this query execution plan, we can tell it is pretty optimal. Lot’s of PK are involved, not that many rows are estimated to be accessed. Please keep in mind that, in joins, we need to multiply rows accessed on every step to get the total number of combinations - here we have 1 x 13 x 1 = 13 rows. This is pretty important as, when joining multiple tables, you can easily end up scanning billions of rows if your joins are not indexed properly. Obviously, an unoptimized join query will not work as expected and it may cause significant impact on the system.
Partitions
Partitions are great tool to manage large amounts of data. If we partition our table using temporal columns, we can easily rotate old data away and keep the recent data close together for better performance and lower fragmentation. Partitions can also be used to speed up queries - this process is called partition pruning. As long as we have in a WHERE clause the column which is used to partition a table, it may be possible to use that condition to access only relevant partitions. Let’s look at an example to illustrate this.
This time we are going to use an ‘employees’ database. We want to find first and last name of employees who had a title of ‘Technique Leader’ between ‘1994-10-31’ and ‘1996-03-31’.
Definition of table ‘title’ looks as follows.
mysql> SHOW CREATE TABLE titles\G
*************************** 1. row ***************************
Table: titles
Create Table: CREATE TABLE `titles` (
`emp_no` int(11) NOT NULL,
`title` varchar(50) NOT NULL,
`from_date` date NOT NULL,
`to_date` date DEFAULT NULL,
PRIMARY KEY (`emp_no`,`title`,`from_date`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
/*!50500 PARTITION BY RANGE COLUMNS(from_date)
(PARTITION p01 VALUES LESS THAN ('1985-12-31') ENGINE = InnoDB,
PARTITION p02 VALUES LESS THAN ('1986-12-31') ENGINE = InnoDB,
PARTITION p03 VALUES LESS THAN ('1987-12-31') ENGINE = InnoDB,
PARTITION p04 VALUES LESS THAN ('1988-12-31') ENGINE = InnoDB,
PARTITION p05 VALUES LESS THAN ('1989-12-31') ENGINE = InnoDB,
PARTITION p06 VALUES LESS THAN ('1990-12-31') ENGINE = InnoDB,
PARTITION p07 VALUES LESS THAN ('1991-12-31') ENGINE = InnoDB,
PARTITION p08 VALUES LESS THAN ('1992-12-31') ENGINE = InnoDB,
PARTITION p09 VALUES LESS THAN ('1993-12-31') ENGINE = InnoDB,
PARTITION p10 VALUES LESS THAN ('1994-12-31') ENGINE = InnoDB,
PARTITION p11 VALUES LESS THAN ('1995-12-31') ENGINE = InnoDB,
PARTITION p12 VALUES LESS THAN ('1996-12-31') ENGINE = InnoDB,
PARTITION p13 VALUES LESS THAN ('1997-12-31') ENGINE = InnoDB,
PARTITION p14 VALUES LESS THAN ('1998-12-31') ENGINE = InnoDB,
PARTITION p15 VALUES LESS THAN ('1999-12-31') ENGINE = InnoDB,
PARTITION p16 VALUES LESS THAN ('2000-12-31') ENGINE = InnoDB,
PARTITION p17 VALUES LESS THAN ('2001-12-31') ENGINE = InnoDB,
PARTITION p18 VALUES LESS THAN ('2002-12-31') ENGINE = InnoDB,
PARTITION p19 VALUES LESS THAN (MAXVALUE) ENGINE = InnoDB) */
1 row in set (0.00 sec)
Please note that we have a lot of partitions created using ‘from_date’ column. To see how we can leverage partitioning to speed up queries, we can use ‘PARTITIONS’ clause in EXPLAIN:
mysql> EXPLAIN PARTITIONS SELECT e.first_name, e.last_name FROM employees AS e JOIN titles AS t ON e.emp_no = t.emp_no WHERE from_date > '1994-10-31' AND from_date < '1996-03-31' AND t.title='Technique Leader'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t
partitions: p10,p11,p12
type: index
possible_keys: PRIMARY
key: PRIMARY
key_len: 59
ref: NULL
rows: 99697
Extra: Using where; Using index
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: e
partitions: NULL
type: eq_ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 4
ref: employees.t.emp_no
rows: 1
Extra: NULL
2 rows in set (0.00 sec)
As you can see, one new column (‘partitions’) was added. It contains values ‘p10,p11,p12’. This means that optimizer, based on the WHERE condition, decided that relevant data is located only in those partitions. Others won’t be accessed. Given the ‘type: index’, the table will be scanned using PRIMARY key to locate matching rows. As a next step, WHERE condition will be applied to locate rows with title='Technique Leader'. Finally, ‘employees’ table will be joined using it’s PK.
EXPLAIN EXTENDED
A query, before being executed, is parsed by the optimizer. This can involve some optimizations and query rewriting. To see what exactly will be executed we can use EXPLAIN EXTENDED followed by ‘SHOW WARNINGS’. Let’s take a look at a couple of examples. First, a simple one:
mysql> EXPLAIN EXTENDED SELECT hire_date FROM employees AS e JOIN salaries AS t USING(emp_no) WHERE salary < 1000+20*100\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: e
type: ALL
possible_keys: PRIMARY
key: NULL
key_len: NULL
ref: NULL
rows: 299423
filtered: 100.00
Extra: NULL
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: t
type: ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 4
ref: employees.e.emp_no
rows: 1
filtered: 100.00
Extra: Using where
2 rows in set, 1 warning (0.00 sec)
mysql> SHOW WARNINGS\G
*************************** 1. row ***************************
Level: Note
Code: 1003
Message: /* select#1 */ select `employees`.`e`.`hire_date` AS `hire_date` from `employees`.`employees` `e` join `employees`.`salaries` `t` where ((`employees`.`t`.`emp_no` = `employees`.`e`.`emp_no`) and (`employees`.`t`.`salary` < <cache>((1000 + (20 * 100)))))
The most important part here is the fact that MySQL does not calculate our salary value all the time - it’s a constant so it can be cached. Additionally, as you may have noticed, we used USING(emp_no) in our JOIN, it was rewritten to WHERE condition which will give us the same result.
Another, more complex example. Please disregard the query itself as it doesn’t have much sense, we want here a query which will show us some additional data in the ‘Warnings’ part:
mysql> EXPLAIN EXTENDED SELECT e.first_name, e.last_name, gender IN (SELECT gender FROM employees e1 WHERE e1.emp_no = 10012 ) FROM employees AS e JOIN titles AS t ON e.emp_no = t.emp_no WHERE from_date > '1994-10-31' AND from_date < '1996-03-31' AND t.title='Technique Leader'\G
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: t
type: index
possible_keys: PRIMARY
key: PRIMARY
key_len: 59
ref: NULL
rows: 99697
filtered: 75.00
Extra: Using where; Using index
*************************** 2. row ***************************
id: 1
select_type: PRIMARY
table: e
type: eq_ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 4
ref: employees.t.emp_no
rows: 1
filtered: 100.00
Extra: NULL
*************************** 3. row ***************************
id: 2
select_type: SUBQUERY
table: e1
type: const
possible_keys: PRIMARY
key: PRIMARY
key_len: 4
ref: const
rows: 1
filtered: 100.00
Extra: NULL
3 rows in set, 1 warning (0.00 sec)
mysql> SHOW WARNINGS\G
*************************** 1. row ***************************
Level: Note
Code: 1003
Message: /* select#1 */ select `employees`.`e`.`first_name` AS `first_name`,`employees`.`e`.`last_name` AS `last_name`,<in_optimizer>(`employees`.`e`.`gender`,`employees`.`e`.`gender` in ( <materialize> (/* select#2 */ select 'M' from `employees`.`employees` `e1` where 1 ), <primary_index_lookup>(`employees`.`e`.`gender` in <temporary table> on <auto_key> where ((`employees`.`e`.`gender` = `materialized-subquery`.`gender`))))) AS `gender IN (SELECT gender FROM employees e1 WHERE e1.emp_no = 10012 )` from `employees`.`employees` `e` join `employees`.`titles` `t` where ((`employees`.`e`.`emp_no` = `employees`.`t`.`emp_no`) and (`employees`.`t`.`title` = 'Technique Leader') and (`employees`.`t`.`from_date` > '1994-10-31') and (`employees`.`t`.`from_date` < '1996-03-31'))
1 row in set (0.00 sec)
Here, the most interesting part is the one regarding subquery:
<in_optimizer>(`employees`.`e`.`gender`,`employees`.`e`.`gender` in ( <materialize> (/* select#2 */ select 'M' from `employees`.`employees` `e1` where 1 ), <primary_index_lookup>(`employees`.`e`.`gender` in <temporary table> on <auto_key> where ((`employees`.`e`.`gender` = `materialized-subquery`.`gender`))))) AS `gender
As can be seen, optimizer detected IN() subquery and ‘in_optimizer’ kicked in. SELECT gender FROM employees e1 WHERE e1.emp_no = 10012 is an independent subquery therefore an obvious step was to make it a constant - but this is not exactly how the optimizer intends to execute this query. Instead it plans to materialize it (create a temporary table) and then join it to the rest of the tables using an automatically created index.
EXPLAIN FORMAT=JSON
Last but not least, EXPLAIN in MySQL 5.6 gives you the nice ability to print the query execution time in JSON format. This is great for any developer who wants to build some tools that will generate a visual representation of the execution plan. It’s also nice for DBA’s as it gives us some additional information about the plan. For example, please note that in the last example in the previous chapter, you didn’t see any information about subquery materialization in the EXPLAIN output - we had to check the additional output from SHOW WARNINGS. Let’s see what we can get if we run EXPLAIN in JSON format:
mysql> EXPLAIN FORMAT=JSON SELECT e.first_name, e.last_name, gender IN (SELECT gender FROM employees e1 WHERE e1.emp_no = 10012 ) FROM employees AS e JOIN titles AS t ON e.emp_no = t.emp_no WHERE from_date > '1994-10-31' AND from_date < '1996-03-31' AND t.title='Technique Leader'\G
*************************** 1. row ***************************
EXPLAIN: {
"query_block": {
"select_id": 1,
"nested_loop": [
{
"table": {
"table_name": "t",
"partitions": [
"p10",
"p11",
"p12"
],
"access_type": "index",
"possible_keys": [
"PRIMARY"
],
"key": "PRIMARY",
"used_key_parts": [
"emp_no",
"title",
"from_date"
],
"key_length": "59",
"rows": 99697,
"filtered": 75,
"using_index": true,
"attached_condition": "((`employees`.`t`.`title` = 'Technique Leader') and (`employees`.`t`.`from_date` > '1994-10-31') and (`employees`.`t`.`from_date` < '1996-03-31'))"
}
},
{
"table": {
"table_name": "e",
"access_type": "eq_ref",
"possible_keys": [
"PRIMARY"
],
"key": "PRIMARY",
"used_key_parts": [
"emp_no"
],
"key_length": "4",
"ref": [
"employees.t.emp_no"
],
"rows": 1,
"filtered": 100
}
}
],
"select_list_subqueries": [
{
"table": {
"table_name": "<materialized_subquery>",
"access_type": "eq_ref",
"key": "<auto_key>",
"key_length": "1",
"rows": 1,
"materialized_from_subquery": {
"using_temporary_table": true,
"dependent": true,
"cacheable": false,
"query_block": {
"select_id": 2,
"table": {
"table_name": "e1",
"access_type": "const",
"possible_keys": [
"PRIMARY"
],
"key": "PRIMARY",
"used_key_parts": [
"emp_no"
],
"key_length": "4",
"ref": [
"const"
],
"rows": 1,
"filtered": 100
}
}
}
}
}
]
}
}
1 row in set, 1 warning (0.00 sec)
There’s a lot of new data. For starters, we can see useful information in ‘used_key_parts’ section. Instead of guessing which parts of the composite index were used in the query, we have a nice list presented in the explain’s output. We have also precise information about what’s going on with the subquery in SELECT’s list. Let’s go over it step by step.
"select_list_subqueries": [
{
"table": {
"table_name": "<materialized_subquery>",
"access_type": "eq_ref",
"key": "<auto_key>",
"key_length": "1",
"rows": 1,
We see it’s a materialized subquery and a single row will be accessed from it for every row in the outer query. We see that an index was automatically created and the table will contain a single row.
"materialized_from_subquery": {
"using_temporary_table": true,
"dependent": true,
"cacheable": false,
This is the interesting part - a subquery was materialized using temporary table and the optimizer decided it’s a dependent subquery - something which is not exactly true. If a query is dependent on the outer query, it can’t be cached as a constant and a materialized table needs to be joined to the outer query. It’s much better than executing the subquery every time but it does not look ideal. On the other hand, it can be as optimal as using a constant, it depends on how MySQL handles constant values - it could as well put them into temp tables which basically would be exactly the same what it does now. The answer to this question would require checking source code.
"query_block": {
"select_id": 2,
"table": {
"table_name": "e1",
"access_type": "const",
"possible_keys": [
"PRIMARY"
],
"key": "PRIMARY",
"used_key_parts": [
"emp_no"
],
"key_length": "4",
"ref": [
"const"
],
"rows": 1,
"filtered": 100
The rest of the data contains information about how the materialized subquery was created - e1 table (employees) was queried using PK lookup, a single row was returned.
We need to comment on the ‘filtered’ column which can be seen across this blog post - for now, please disregard it. It will tell us about the number of rows that should be filtered by a given table condition. This will be an estimate only and it is available in MySQL 5.7. In 5.6, the data is not really reliable.
EXPLAIN is really a great tool which can help you to understand your queries. It may look complex (and it is definitely not easy to master), but the time you spend trying to solve its mysteries will be of great benefit for you. In the end, faster, better optimized queries means happier MySQL :-)
In the next post in the series we are going to look into how we can impact optimizer’s decisions and generate more efficient query execution plans.