Introduction
Docker modernized the way we build and deploy the application. It allows us to create lightweight, portable, self sufficient containers that can run any application easily.
This blog intended to explain how to use Docker to run PostgreSQL database. It doesn’t cover installation or configuration of docker. Please refer docker installation instructions here. Some additional background can be found in our previous blog on MySQL and Docker.
Before going into the details, let’s review some terminology.
- Dockerfile
It contains the set of instructions/commands to install or configure the application/software. - Docker Image
Docker image is built up from series of layers which represent instructions from the Dockerfile. Docker image is used as a template to create a container. - Linking of containers and user defined networking
Docker used bridge as a default networking mechanism and use the --links to link the containers to each other. For accessing PostgreSQL container from an application container, one should link both containers at creation time. Here in this article we are using user defined networks as link feature will soon be deprecated. - Data persistence in Docker
By default, data inside a container is ephemeral. Whenever the container gets restarted, data will be lost. Volumes are the preferred mechanism to persist data generated and used by a Docker container. Here, we are mounting a host directory inside the container where all the data is stored.
Let’s start to build our PostgreSQL image and use it to run a container.
PostgreSQL Dockerfile
# example Dockerfile for https://docs.docker.com/engine/examples/postgresql_service/
FROM ubuntu:14.04
# Add the PostgreSQL PGP key to verify their Debian packages.
# It should be the same key as https://www.postgresql.org/media/keys/ACCC4CF8.asc
RUN apt-key adv --keyserver hkp://p80.pool.sks-keyservers.net:80 --recv-keys B97B0AFCAA1A47F044F244A07FCC7D46ACCC4CF8
# Add PostgreSQL's repository. It contains the most recent stable release
# of PostgreSQL, ``9.3``.
RUN echo "deb http://apt.postgresql.org/pub/repos/apt/ precise-pgdg main"> /etc/apt/sources.list.d/pgdg.list
# Install ``python-software-properties``, ``software-properties-common`` and PostgreSQL 9.3
# There are some warnings (in red) that show up during the build. You can hide
# them by prefixing each apt-get statement with DEBIAN_FRONTEND=noninteractive
RUN apt-get update && apt-get install -y python-software-properties software-properties-common postgresql-9.3 postgresql-client-9.3 postgresql-contrib-9.3
# Note: The official Debian and Ubuntu images automatically ``apt-get clean``
# after each ``apt-get``
# Run the rest of the commands as the ``postgres`` user created by the ``postgres-9.3`` package when it was ``apt-get installed``
USER postgres
# Create a PostgreSQL role named ``postgresondocker`` with ``postgresondocker`` as the password and
# then create a database `postgresondocker` owned by the ``postgresondocker`` role.
# Note: here we use ``&&\`` to run commands one after the other - the ``\``
# allows the RUN command to span multiple lines.
RUN /etc/init.d/postgresql start &&\
psql --command "CREATE USER postgresondocker WITH SUPERUSER PASSWORD 'postgresondocker';"&&\
createdb -O postgresondocker postgresondocker
# Adjust PostgreSQL configuration so that remote connections to the
# database are possible.
RUN echo "host all all 0.0.0.0/0 md5">> /etc/postgresql/9.3/main/pg_hba.conf
# And add ``listen_addresses`` to ``/etc/postgresql/9.3/main/postgresql.conf``
RUN echo "listen_addresses='*'">> /etc/postgresql/9.3/main/postgresql.conf
# Expose the PostgreSQL port
EXPOSE 5432
# Add VOLUMEs to allow backup of config, logs and databases
VOLUME ["/etc/postgresql", "/var/log/postgresql", "/var/lib/postgresql"]
# Set the default command to run when starting the container
CMD ["/usr/lib/postgresql/9.3/bin/postgres", "-D", "/var/lib/postgresql/9.3/main", "-c", "config_file=/etc/postgresql/9.3/main/postgresql.conf"]If you look at the Dockerfile closely, it consists of commands which are used to install PostgreSQL and perform some configuration changes on ubuntu OS.
Building PostgreSQL Image
We can build a PostgreSQL image from Dockerfile using the docker build command.
# sudo docker build -t postgresondocker:9.3 .Here, we can specify the tag (-t) to the image like name and version. Dot (.) at the end specifies the current directory and it uses the Dockerfile present in the current directory.Docker file name should be “Dockerfile”. If you want to specify a custom name for your docker file then you should use -f <your_dockerfile_name> in the docker build command.
# sudo docker build -t postgresondocker:9.3 -f <your_docker_file_name>Output: (Optional use scroll bar text window if possible)
Sending build context to Docker daemon 4.096kB
Step 1/11 : FROM ubuntu:14.04
14.04: Pulling from library/ubuntu
324d088ce065: Pull complete
2ab951b6c615: Pull complete
9b01635313e2: Pull complete
04510b914a6c: Pull complete
83ab617df7b4: Pull complete
Digest: sha256:b8855dc848e2622653ab557d1ce2f4c34218a9380cceaa51ced85c5f3c8eb201
Status: Downloaded newer image for ubuntu:14.04
---> 8cef1fa16c77
Step 2/11 : RUN apt-key adv --keyserver hkp://p80.pool.sks-keyservers.net:80 --recv-keys B97B0AFCAA1A47F044F244A07FCC7D46ACCC4CF8
---> Running in ba933d07e226
.
.
.
fixing permissions on existing directory /var/lib/postgresql/9.3/main ... ok
creating subdirectories ... ok
selecting default max_connections ... 100
selecting default shared_buffers ... 128MB
creating configuration files ... ok
creating template1 database in /var/lib/postgresql/9.3/main/base/1 ... ok
initializing pg_authid ... ok
initializing dependencies ... ok
creating system views ... ok
loading system objects' descriptions ... ok
creating collations ... ok
creating conversions ... ok
creating dictionaries ... ok
setting privileges on built-in objects ... ok
creating information schema ... ok
loading PL/pgSQL server-side language ... ok
vacuuming database template1 ... ok
copying template1 to template0 ... ok
copying template1 to postgres ... ok
syncing data to disk ... ok
Success. You can now start the database server using:
/usr/lib/postgresql/9.3/bin/postgres -D /var/lib/postgresql/9.3/main
or
/usr/lib/postgresql/9.3/bin/pg_ctl -D /var/lib/postgresql/9.3/main -l logfile start
Ver Cluster Port Status Owner Data directory Log file
9.3 main 5432 down postgres /var/lib/postgresql/9.3/main /var/log/postgresql/postgresql-9.3-main.log
update-alternatives: using /usr/share/postgresql/9.3/man/man1/postmaster.1.gz to provide /usr/share/man/man1/postmaster.1.gz (postmaster.1.gz) in auto mode
invoke-rc.d: policy-rc.d denied execution of start.
Setting up postgresql-contrib-9.3 (9.3.22-0ubuntu0.14.04) ...
Setting up python-software-properties (0.92.37.8) ...
Setting up python3-software-properties (0.92.37.8) ...
Setting up software-properties-common (0.92.37.8) ...
Processing triggers for libc-bin (2.19-0ubuntu6.14) ...
Processing triggers for ca-certificates (20170717~14.04.1) ...
Updating certificates in /etc/ssl/certs... 148 added, 0 removed; done.
Running hooks in /etc/ca-certificates/update.d....done.
Processing triggers for sgml-base (1.26+nmu4ubuntu1) ...
Removing intermediate container fce692f180bf
---> 9690b681044b
Step 5/11 : USER postgres
---> Running in ff8864c1147d
Removing intermediate container ff8864c1147d
---> 1f669efeadfa
Step 6/11 : RUN /etc/init.d/postgresql start && psql --command "CREATE USER postgresondocker WITH SUPERUSER PASSWORD 'postgresondocker';"&& createdb -O postgresondocker postgresondocker
---> Running in 79042024b5e8
* Starting PostgreSQL 9.3 database server
...done.
CREATE ROLE
Removing intermediate container 79042024b5e8
---> 70c43a9dd5ab
Step 7/11 : RUN echo "host all all 0.0.0.0/0 md5">> /etc/postgresql/9.3/main/pg_hba.conf
---> Running in c4d03857cdb9
Removing intermediate container c4d03857cdb9
---> 0cc2ed249aab
Step 8/11 : RUN echo "listen_addresses='*'">> /etc/postgresql/9.3/main/postgresql.conf
---> Running in fde0f721c846
Removing intermediate container fde0f721c846
---> 78263aef9a56
Step 9/11 : EXPOSE 5432
---> Running in a765f854a274
Removing intermediate container a765f854a274
---> d205f9208162
Step 10/11 : VOLUME ["/etc/postgresql", "/var/log/postgresql", "/var/lib/postgresql"]
---> Running in ae0b9f30f3d0
Removing intermediate container ae0b9f30f3d0
---> 0de941f8687c
Step 11/11 : CMD ["/usr/lib/postgresql/9.3/bin/postgres", "-D", "/var/lib/postgresql/9.3/main", "-c", "config_file=/etc/postgresql/9.3/main/postgresql.conf"]
---> Running in 976d283ea64c
Removing intermediate container 976d283ea64c
---> 253ee676278f
Successfully built 253ee676278f
Successfully tagged postgresondocker:9.3Container Network Creation
Use below command to create a user defined network with bridge driver.
# sudo docker network create --driver bridge postgres-networkConfirm Network Creation
# sudo docker network ls
NETWORK ID NAME DRIVER SCOPE
a553e5727617 bridge bridge local
0c6e40305851 host host local
4cca2679d3c0 none null local
83b23e0af641 postgres-network bridge localContainer Creation
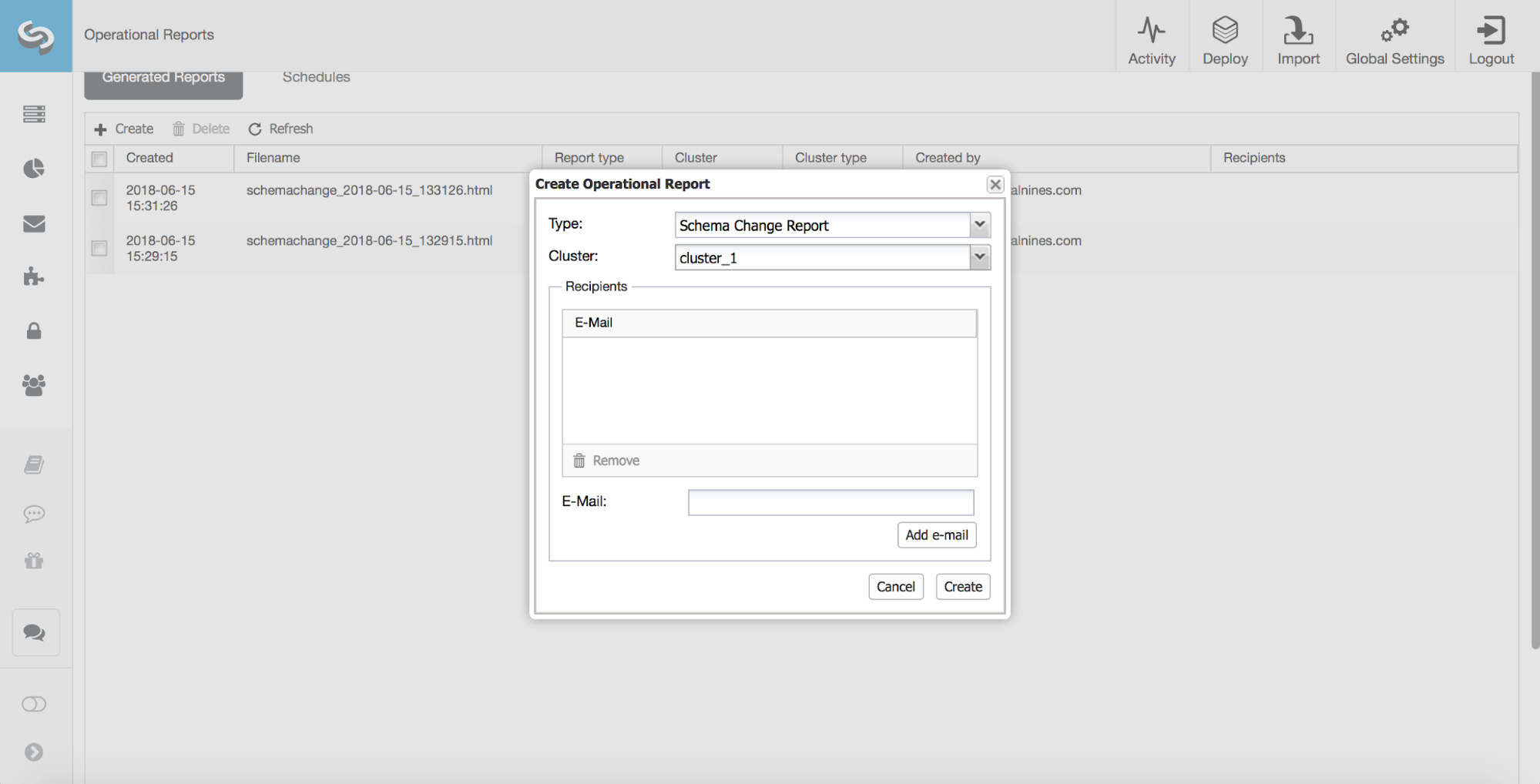
We need to use “docker run” command to create a container from the docker image. We are running postgres container in daemonize mode with the help of -d option.
# sudo docker run --name postgresondocker --network postgres-network -d postgresondocker:9.3Use below command to confirm the container creation.
# sudo docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
06a5125f5e11 postgresondocker:9.3 "/usr/lib/postgresql…" About a minute ago Up About a minute 5432/tcp postgresondockerWe have not specified any port to expose, so it will expose the default postgres port 5432 for internal use. PostgreSQL is available only from inside the Docker network, we will not able to access this Postgres container on a host port.
We will see how to access Postgres container on host port in a later section in this article.
Connecting to PostgreSQL container inside Docker network
Let’s try to connect to the Postgres container from another container within the same Docker network which we created earlier.Here, we have used psql client to connect to the Postgres. We used the Postgres container name as a hostname, user and password present in the Docker file.
# docker run -it --rm --network postgres-network postgresondocker:9.3 psql -h postgresondocker -U postgresondocker --password
Password for user postgresondocker:
psql (9.3.22)
SSL connection (cipher: DHE-RSA-AES256-GCM-SHA384, bits: 256)
Type "help" for help.
postgresondocker=# The --rm option in run command will remove the container once we terminate the psql process.
# sudo docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
2fd91685d1ea postgresondocker:9.3 "psql -h postgresond…" 29 seconds ago Up 30 seconds 5432/tcp brave_spence
06a5125f5e11 postgresondocker:9.3 "/usr/lib/postgresql…" About a minute ago Up About a minute 5432/tcp postgresondockerData persistence
Docker containers are ephemeral in nature, i.e. data which is used or generated by the container is not stored anywhere implicitly. We lose the data whenever the container gets restarted or deleted. Docker provides volumes on which we can store the persistent data. It is a useful feature by which we can provision another container using the same volume or data in case of disaster.
Let's create a data volume and confirm its creation.
# sudo docker volume create pgdata
pgdata
# sudo docker volume ls
DRIVER VOLUME NAME
local pgdataNow we have to use this data volume while running the Postgres container. Make sure you delete the older postgres container which is running without volumes.
# sudo docker container rm postgresondocker -f
postgresondocker
# sudo docker run --name postgresondocker --network postgres-network -v pgdata:/var/lib/postgresql/9.3/main -d postgresondocker:9.3We have ran the Postgres container with a data volume attached to it.
Create a new table in Postgres to check data persistence.
# docker run -it --rm --network postgres-network postgresondocker:9.3 psql -h postgresondocker -U postgresondocker --password
Password for user postgresondocker:
psql (9.3.22)
SSL connection (cipher: DHE-RSA-AES256-GCM-SHA384, bits: 256)
Type "help" for help.
postgresondocker=# \dt
No relations found.
postgresondocker=# create table test(id int);
CREATE TABLE
postgresondocker=# \dt
List of relations
Schema | Name | Type | Owner
--------+------+-------+------------------
public | test | table | postgresondocker
(1 row)Delete the Postgres container.
# sudo docker container rm postgresondocker -f
postgresondockerCreate a new Postgres container and confirm the test table present or not.
# sudo docker run --name postgresondocker --network postgres-network -v pgdata:/var/lib/postgresql/9.3/main -d postgresondocker:9.3
# docker run -it --rm --network postgres-network postgresondocker:9.3 psql -h postgresondocker -U postgresondocker --password
Password for user postgresondocker:
psql (9.3.22)
SSL connection (cipher: DHE-RSA-AES256-GCM-SHA384, bits: 256)
Type "help" for help.
postgresondocker=# \dt
List of relations
Schema | Name | Type | Owner
--------+------+-------+------------------
public | test | table | postgresondocker
(1 row)Expose PostgreSQL service to the host
You may have noticed that we have not exposed any port of the PostgreSQL container earlier. This means that PostgreSQL is only accessible to the containers that are in the postgres-network we created earlier.
To use PostgreSQL service we need to expose container port using --port option. Here, we have exposed the Postgres container port 5432 on 5432 port of the host.
# sudo docker run --name postgresondocker --network postgres-network -v pgdata:/var/lib/postgresql/9.3/main -p 5432:5432 -d postgresondocker:9.3
# sudo docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
997580c86188 postgresondocker:9.3 "/usr/lib/postgresql…" 8 seconds ago Up 10 seconds 0.0.0.0:5432->5432/tcp postgresondockerNow you can connect PostgreSQL on localhost directly.
# psql -h localhost -U postgresondocker --password
Password for user postgresondocker:
psql (9.3.22)
SSL connection (cipher: DHE-RSA-AES256-GCM-SHA384, bits: 256)
Type "help" for help.
postgresondocker=#Container Deletion
To delete the container, we need to stop the running container first and then delete the container using rm command.
# sudo docker container stop postgresondocker
# sudo docker container rm postgresondocker
postgresondockerUse -f (--force) option to directly delete the running container.
# sudo docker container rm postgresondocker -f
postgresondockerHopefully, you now have your own dockerized local environment for PostgreSQL.
Note: This article provides an overview about how we can use PostgreSQL on docker for development/POC environment. Running PostgreSQL in production environment may require additional changes in the PostgreSQL or docker configurations.
Conclusion
There is a simple way to run PostgreSQL database inside a Docker container. Docker effectively encapsulates deployment, configuration and certain administration procedures. Docker is a good choice to deploy PostgreSQL with minimum efforts. All you need to do is start a pre-built Docker container and you will have PostgreSQL database ready for your service.
References
- Docker installation: https://docs.docker.com/install
- Volumes: https://docs.docker.com/storage/volumes
- User Defined networks: https://docs.docker.com/network/
- Postgres Docker File: https://docs.docker.com/engine/examples/postgresql_service
- MySQL on Docker: Understanding the Basics: https://severalnines.com/blog/mysql-docker-containers-understanding-basics