How to run analytics on MySQL?
MySQL is a great database for Online Transaction Processing (OLTP) workloads. For some companies, it used to be more than enough for a long time. Times have changed and the business requirements along with them. As businesses aspire to be more data-driven, more and more data is stored for further analysis; customer behavior, performance patterns, network traffic, logs, etc. No matter what industry you are in, it is very likely that there is data which you want to keep and analyze to better understand what is going on and how to improve your business. Unfortunately, for storing and querying the large amount of data, MySQL is not the best option. Sure, it can do it and it has tools to help accommodate large amounts of data (e.g.,InnoDB compression), but using a dedicated solution for Online Analytics Processing (OLAP) most likely will greatly improve your ability to store and query a large quantity of data.
One way of tackling this problem will be to use a dedicated database for running analytics. Typically, you want to use a columnar datastore for such tasks - they are more suitable for handling large quantities of data: data stored in columns typically is easier to compress, it is also easier to access on per column basis - typically you ask for some data stored in a couple of columns - an ability to retrieve just those columns instead of reading all of the rows and filter out unneeded data makes the data accessed faster.
How to replicate data from MySQL to ClickHouse?
An example of the columnar datastore which is suitable for analytics is ClickHouse, an open source column store. One challenge is to ensure the data in ClickHouse is in sync with the data in MySQL. Sure, it is always possible to setup a data pipeline of some sort and perform automated batch loading into ClickHouse. But as long as you can live with some limitations, there’s a better way of setting up almost real-time replication from MySQL into ClickHouse. In this blog post we will take a look at how it can be done.
ClickHouse installation
First of all we need to install ClickHouse. We’ll use the quickstart from the ClickHouse website.
sudo apt-get install dirmngr # optional
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv E0C56BD4 # optional
echo "deb http://repo.yandex.ru/clickhouse/deb/stable/ main/" | sudo tee /etc/apt/sources.list.d/clickhouse.list
sudo apt-get update
sudo apt-get install -y clickhouse-server clickhouse-client
sudo service clickhouse-server startOnce this is done, we need to find a means to transfer the data from MySQL into ClickHouse. One of the possible solutions is to use Altinity’s clickhouse-mysql-data-reader. First of all, we have to install pip3 (python3-pip in Ubuntu) as Python in version at least 3.4 is required. Then we can use pip3 to install some of the required Python modules:
pip3 install mysqlclient
pip3 install mysql-replication
pip3 install clickhouse-driverOnce this is done, we have to clone the repository. For Centos 7, RPM’s are also available, it is also possible to install it using pip3 (clickhouse-mysql package) but we found that the version available through pip does not contain the latest updates and we want to use master branch from git repository:
git clone https://github.com/Altinity/clickhouse-mysql-data-readerThen, we can install it using pip:
pip3 install -e /path/to/clickhouse-mysql-data-reader/Next step will be to create MySQL users required by clickhouse-mysql-data-reader to access MySQL data:
mysql> CREATE USER 'chreader'@'%' IDENTIFIED BY 'pass';
Query OK, 0 rows affected (0.02 sec)
mysql> CREATE USER 'chreader'@'127.0.0.1' IDENTIFIED BY 'pass';
Query OK, 0 rows affected (0.00 sec)
mysql> CREATE USER 'chreader'@'localhost' IDENTIFIED BY 'pass';
Query OK, 0 rows affected (0.02 sec)
mysql> GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE, SUPER ON *.* TO 'chreader'@'%';
Query OK, 0 rows affected (0.01 sec)
mysql> GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE, SUPER ON *.* TO 'chreader'@'127.0.0.1';
Query OK, 0 rows affected (0.00 sec)
mysql> GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE, SUPER ON *.* TO 'chreader'@'localhost';
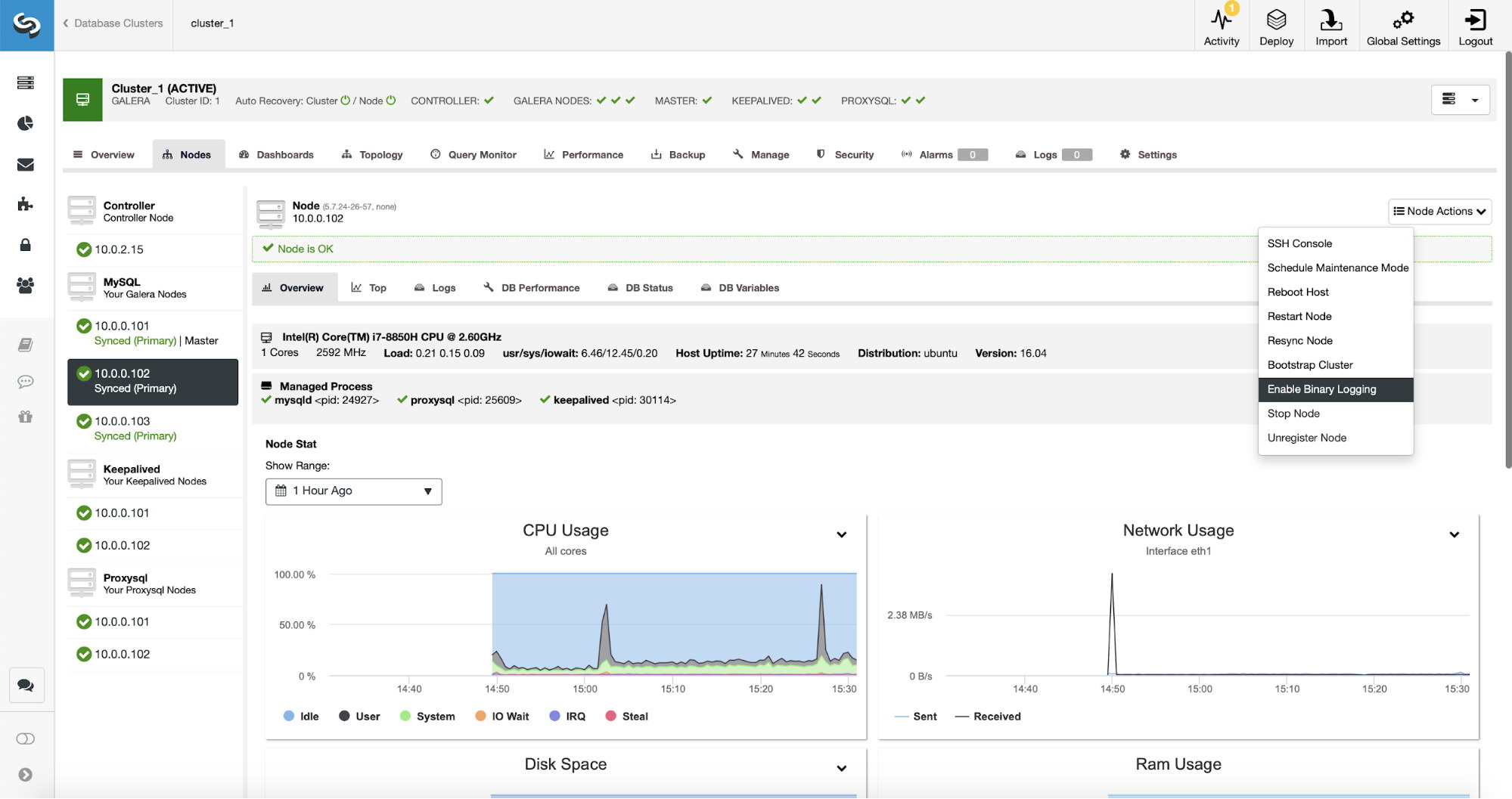
Query OK, 0 rows affected, 1 warning (0.01 sec)You should also review your MySQL configuration to ensure you have binary logs enabled, max_binlog_size is set to 768M, binlogs are in ‘row’ format and that the tool can connect to the MySQL. Below is an excerpt from the documentation:
[mysqld]
# mandatory
server-id = 1
log_bin = /var/lib/mysql/bin.log
binlog-format = row # very important if you want to receive write, update and delete row events
# optional
expire_logs_days = 30
max_binlog_size = 768M
# setup listen address
bind-address = 0.0.0.0Importing the data
When everything is ready you can import the data into ClickHouse. Ideally you would run the import on a host with tables locked so that no change will happen during the process. You can use a slave as the source of the data. The command to run will be:
clickhouse-mysql --src-server-id=1 --src-wait --nice-pause=1 --src-host=10.0.0.142 --src-user=chreader --src-password=pass --src-tables=wiki.pageviews --dst-host=127.0.0.1 --dst-create-table --migrate-tableIt will connect to MySQL on host 10.0.0.142 using given credentials, it will copy the table ‘pageviews’ in the schema ‘wiki’ to a ClickHouse running on the local host (127.0.0.1). Table will be created automatically and data will be migrated.
For the purpose of this blog we imported roughly 50 million rows from “pageviews” dataset made available by Wikimedia Foundation. The table schema in MySQL is:
mysql> SHOW CREATE TABLE wiki.pageviews\G
*************************** 1. row ***************************
Table: pageviews
Create Table: CREATE TABLE `pageviews` (
`date` date NOT NULL,
`hour` tinyint(4) NOT NULL,
`code` varbinary(255) NOT NULL,
`title` varbinary(1000) NOT NULL,
`monthly` bigint(20) DEFAULT NULL,
`hourly` bigint(20) DEFAULT NULL,
PRIMARY KEY (`date`,`hour`,`code`,`title`)
) ENGINE=InnoDB DEFAULT CHARSET=binary
1 row in set (0.00 sec)The tool translated this into following ClickHouse schema:
vagrant.vm :) SHOW CREATE TABLE wiki.pageviews\G
SHOW CREATE TABLE wiki.pageviews
Row 1:
──────
statement: CREATE TABLE wiki.pageviews ( date Date, hour Int8, code String, title String, monthly Nullable(Int64), hourly Nullable(Int64)) ENGINE = MergeTree(date, (date, hour, code, title), 8192)
1 rows in set. Elapsed: 0.060 sec.Once the import is done, we can compare the contents of MySQL:
mysql> SELECT COUNT(*) FROM wiki.pageviews\G
*************************** 1. row ***************************
COUNT(*): 50986914
1 row in set (24.56 sec)and in ClickHouse:
vagrant.vm :) SELECT COUNT(*) FROM wiki.pageviews\G
SELECT COUNT(*)
FROM wiki.pageviews
Row 1:
──────
COUNT(): 50986914
1 rows in set. Elapsed: 0.014 sec. Processed 50.99 million rows, 50.99 MB (3.60 billion rows/s., 3.60 GB/s.)Even in such a small table you can clearly see that MySQL required more time to scan through it than ClickHouse.
When starting the process to watch the binary log for events, ideally you would pass the information about the binary log file and position from where the tool should start listening. You can easily check that on the slave after the initial import completed.
clickhouse-mysql --src-server-id=1 --src-resume --src-binlog-file='binlog.000016' --src-binlog-position=194 --src-wait --nice-pause=1 --src-host=10.0.0.142 --src-user=chreader --src-password=pass --src-tables=wiki.pageviews --dst-host=127.0.0.1 --pump-data --csvpoolIf you won’t pass it, it will just start listening for anything that comes in:
clickhouse-mysql --src-server-id=1 --src-resume --src-wait --nice-pause=1 --src-host=10.0.0.142 --src-user=chreader --src-password=pass --src-tables=wiki.pageviews --dst-host=127.0.0.1 --pump-data --csvpoolLet’s load some more data and see how it will work out for us. We can see that everything seems ok by looking at the logs of clickhouse-mysql-data-reader:
2019-02-11 15:21:29,705/1549898489.705732:INFO:['wiki.pageviews']
2019-02-11 15:21:29,706/1549898489.706199:DEBUG:class:<class 'clickhouse_mysql.writer.poolwriter.PoolWriter'> insert
2019-02-11 15:21:29,706/1549898489.706682:DEBUG:Next event binlog pos: binlog.000016.42066434
2019-02-11 15:21:29,707/1549898489.707067:DEBUG:WriteRowsEvent #224892 rows: 1
2019-02-11 15:21:29,707/1549898489.707483:INFO:['wiki.pageviews']
2019-02-11 15:21:29,707/1549898489.707899:DEBUG:class:<class 'clickhouse_mysql.writer.poolwriter.PoolWriter'> insert
2019-02-11 15:21:29,708/1549898489.708083:DEBUG:Next event binlog pos: binlog.000016.42066595
2019-02-11 15:21:29,708/1549898489.708659:DEBUG:WriteRowsEvent #224893 rows: 1What we have to keep in mind are the limitations of the tool. The biggest one is that it supports INSERTs only. There’s no support for DELETE or UPDATE. There is also no support for DDL’s therefore any incompatible schema changes executed on MySQL will break the MySQL to ClickHouse replication.
Also worth noting is the fact that the developers of the script recommend to use pypy to improve the performance of the tool. Let’s go through some steps required to set this up.
At first you have to download and decompress pypy:
wget https://bitbucket.org/squeaky/portable-pypy/downloads/pypy3.5-7.0.0-linux_x86_64-portable.tar.bz2
tar jxf pypy3.5-7.0.0-linux_x86_64-portable.tar.bz2
cd pypy3.5-7.0.0-linux_x86_64-portableNext, we have to install pip and all the requirements for the clickhouse-mysql-data-reader - exactly the same things we covered earlier, while describing regular setup:
./bin/pypy -m ensurepip
./bin/pip3 install mysql-replication
./bin/pip3 install clickhouse-driver
./bin/pip3 install mysqlclientLast step will be to install clickhouse-mysql-data-reader from the github repository (we assume it has already been cloned):
./bin/pip3 install -e /path/to/clickhouse-mysql-data-reader/That’s all. Starting from now you should run all the commands using the environment created for pypy:
./bin/pypy ./bin/clickhouse-mysqlTests
Data has been loaded, we can verify that everything went smoothly by comparing the size of the table:
MySQL:
mysql> SELECT COUNT(*) FROM wiki.pageviews\G
*************************** 1. row ***************************
COUNT(*): 204899465
1 row in set (1 min 40.12 sec)ClickHouse:
vagrant.vm :) SELECT COUNT(*) FROM wiki.pageviews\G
SELECT COUNT(*)
FROM wiki.pageviews
Row 1:
──────
COUNT(): 204899465
1 rows in set. Elapsed: 0.100 sec. Processed 204.90 million rows, 204.90 MB (2.04 billion rows/s., 2.04 GB/s.)Everything looks correct. Let’s run some queries to see how ClickHouse behaves. Please keep in mind all this setup is far from production-grade. We used two small VM’s, 4GB of memory, one vCPU each. Therefore even though the dataset wasn’t big, it was enough to see the difference. Due to small sample it is quite hard to do “real” analytics but we still can throw some random queries.
Let’s check what days of the week we have data from and how many pages have been viewed per day in our sample data:
vagrant.vm :) SELECT count(*), toDayOfWeek(date) AS day FROM wiki.pageviews GROUP BY day ORDER BY day ASC;
SELECT
count(*),
toDayOfWeek(date) AS day
FROM wiki.pageviews
GROUP BY day
ORDER BY day ASC
┌───count()─┬─day─┐
│ 50986896 │ 2 │
│ 153912569 │ 3 │
└───────────┴─────┘
2 rows in set. Elapsed: 2.457 sec. Processed 204.90 million rows, 409.80 MB (83.41 million rows/s., 166.82 MB/s.)In case of MySQL this query looks like below:
mysql> SELECT COUNT(*), DAYOFWEEK(date) AS day FROM wiki.pageviews GROUP BY day ORDER BY day;
+-----------+------+
| COUNT(*) | day |
+-----------+------+
| 50986896 | 3 |
| 153912569 | 4 |
+-----------+------+
2 rows in set (3 min 35.88 sec)As you can see, MySQL needed 3.5 minute to do a full table scan.
Now, let’s see how many pages have monthly value greater than 100:
vagrant.vm :) SELECT count(*), toDayOfWeek(date) AS day FROM wiki.pageviews WHERE monthly > 100 GROUP BY day;
SELECT
count(*),
toDayOfWeek(date) AS day
FROM wiki.pageviews
WHERE monthly > 100
GROUP BY day
┌─count()─┬─day─┐
│ 83574 │ 2 │
│ 246237 │ 3 │
└─────────┴─────┘
2 rows in set. Elapsed: 1.362 sec. Processed 204.90 million rows, 1.84 GB (150.41 million rows/s., 1.35 GB/s.)In case of MySQL it’s again 3.5 minutes:
mysql> SELECT COUNT(*), DAYOFWEEK(date) AS day FROM wiki.pageviews WHERE YEAR(date) = 2018 AND monthly > 100 GROUP BY day;
^@^@+----------+------+
| COUNT(*) | day |
+----------+------+
| 83574 | 3 |
| 246237 | 4 |
+----------+------+
2 rows in set (3 min 3.48 sec)Another query, just a lookup based on some string values:
vagrant.vm :) select * from wiki.pageviews where title LIKE 'Main_Page' AND code LIKE 'de.m' AND hour=6;
SELECT *
FROM wiki.pageviews
WHERE (title LIKE 'Main_Page') AND (code LIKE 'de.m') AND (hour = 6)
┌───────date─┬─hour─┬─code─┬─title─────┬─monthly─┬─hourly─┐
│ 2018-05-01 │ 6 │ de.m │ Main_Page │ 8 │ 0 │
└────────────┴──────┴──────┴───────────┴─────────┴────────┘
┌───────date─┬─hour─┬─code─┬─title─────┬─monthly─┬─hourly─┐
│ 2018-05-02 │ 6 │ de.m │ Main_Page │ 17 │ 0 │
└────────────┴──────┴──────┴───────────┴─────────┴────────┘
2 rows in set. Elapsed: 0.015 sec. Processed 66.70 thousand rows, 4.20 MB (4.48 million rows/s., 281.53 MB/s.)Another query, doing some lookups in the string and a condition based on ‘monthly’ column:
vagrant.vm :) select title from wiki.pageviews where title LIKE 'United%Nations%' AND code LIKE 'en.m' AND monthly>100 group by title;
SELECT title
FROM wiki.pageviews
WHERE (title LIKE 'United%Nations%') AND (code LIKE 'en.m') AND (monthly > 100)
GROUP BY title
┌─title───────────────────────────┐
│ United_Nations │
│ United_Nations_Security_Council │
└─────────────────────────────────┘
2 rows in set. Elapsed: 0.083 sec. Processed 1.61 million rows, 14.62 MB (19.37 million rows/s., 175.34 MB/s.)In case of MySQL it looks as below:
mysql> SELECT * FROM wiki.pageviews WHERE title LIKE 'Main_Page' AND code LIKE 'de.m' AND hour=6;
+------------+------+------+-----------+---------+--------+
| date | hour | code | title | monthly | hourly |
+------------+------+------+-----------+---------+--------+
| 2018-05-01 | 6 | de.m | Main_Page | 8 | 0 |
| 2018-05-02 | 6 | de.m | Main_Page | 17 | 0 |
+------------+------+------+-----------+---------+--------+
2 rows in set (2 min 45.83 sec)So, almost 3 minutes. The second query is the same:
mysql> select title from wiki.pageviews where title LIKE 'United%Nations%' AND code LIKE 'en.m' AND monthly>100 group by title;
+---------------------------------+
| title |
+---------------------------------+
| United_Nations |
| United_Nations_Security_Council |
+---------------------------------+
2 rows in set (2 min 40.91 sec)Of course, one can argue that you can add more indexes to improve query performance, but the fact is, adding indexes will require additional data to be stored on disk. Indexes require disk space and they also pose operational challenges - if we are talking about real world OLAP data sets, we are talking about terabytes of data. It takes a lot of time and requires a well-defined and tested process to run schema changes on such environment. This is why dedicated columnar datastores can be very handy and help tremendously to get better insight into all the analytics data that everyone stores.