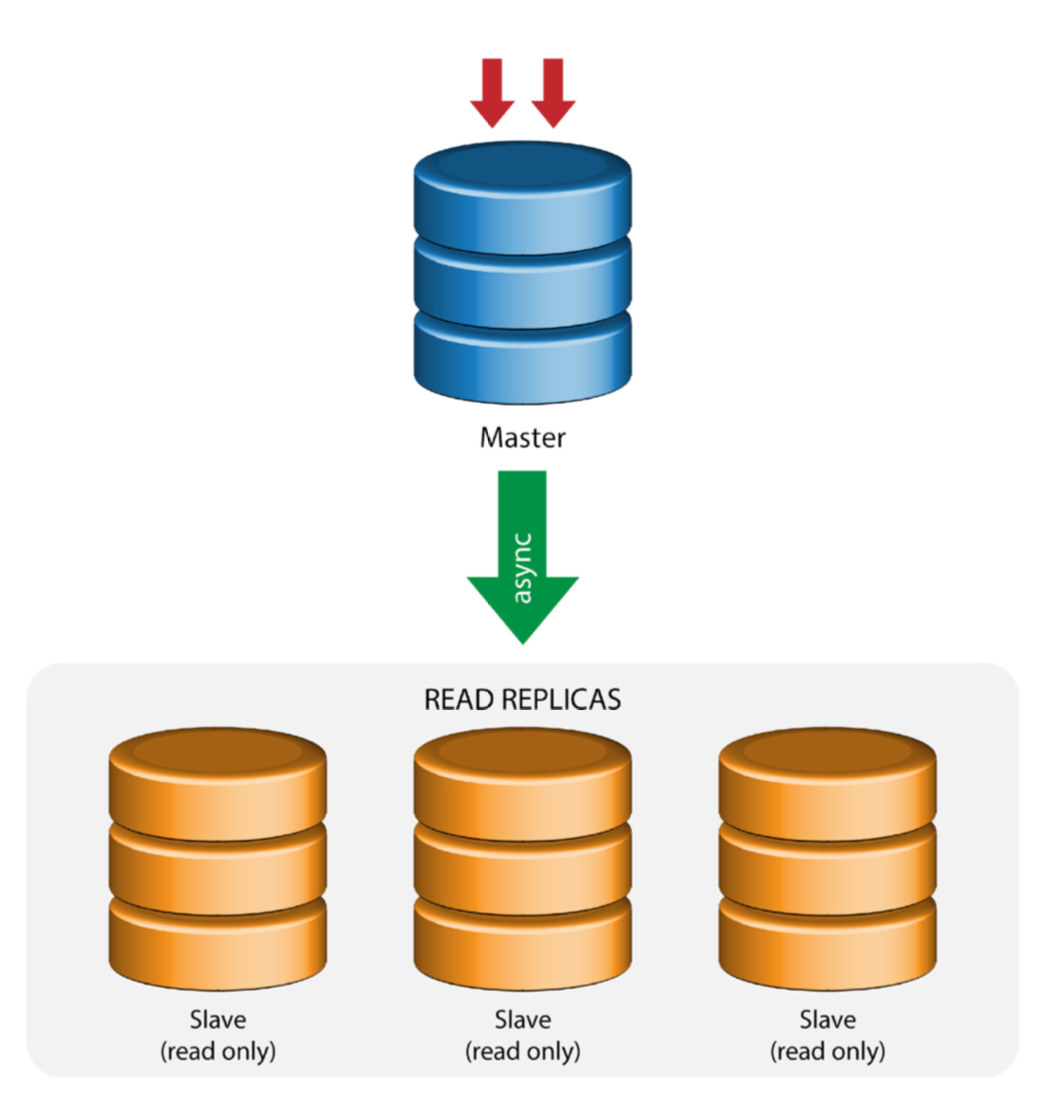
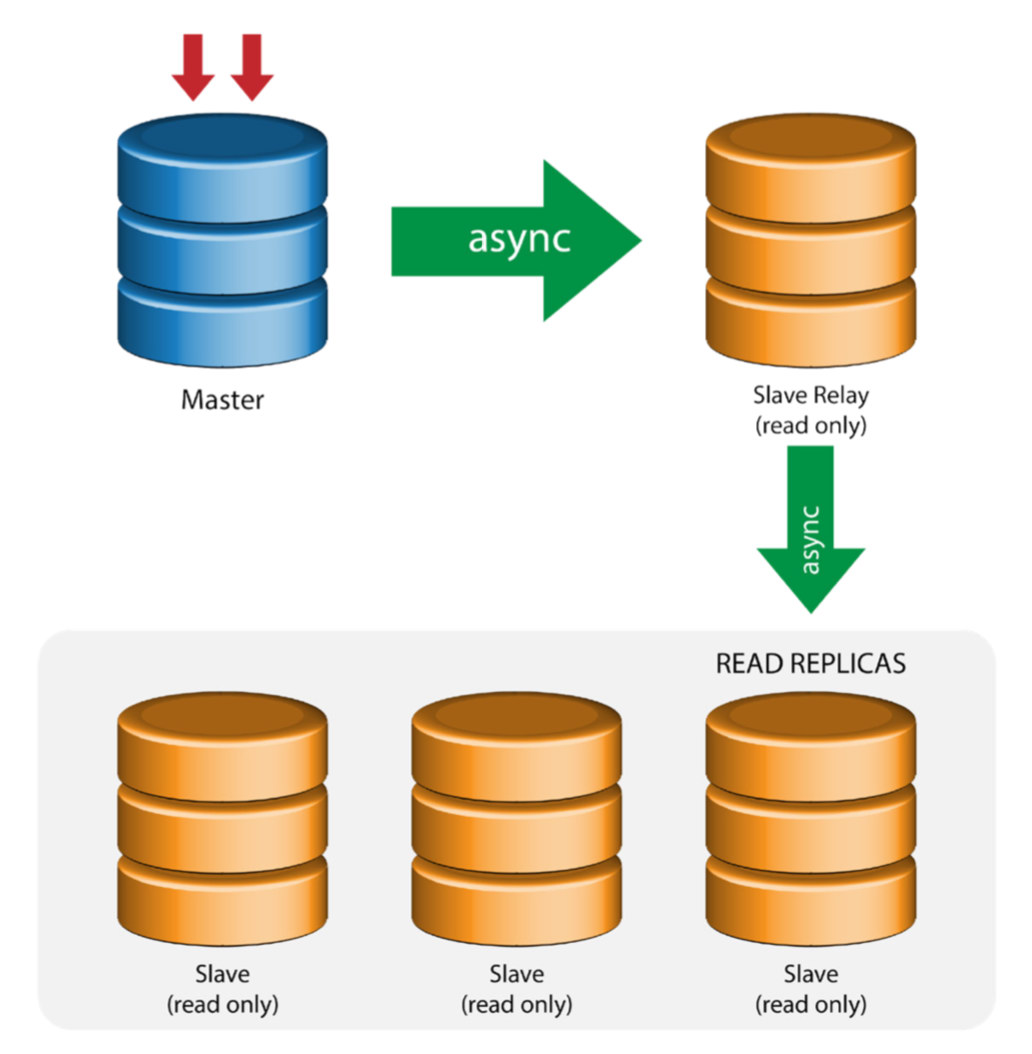
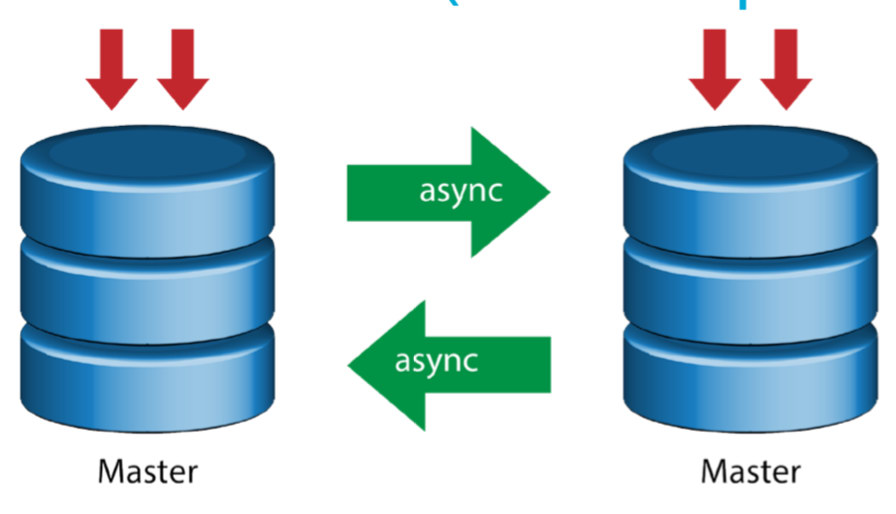
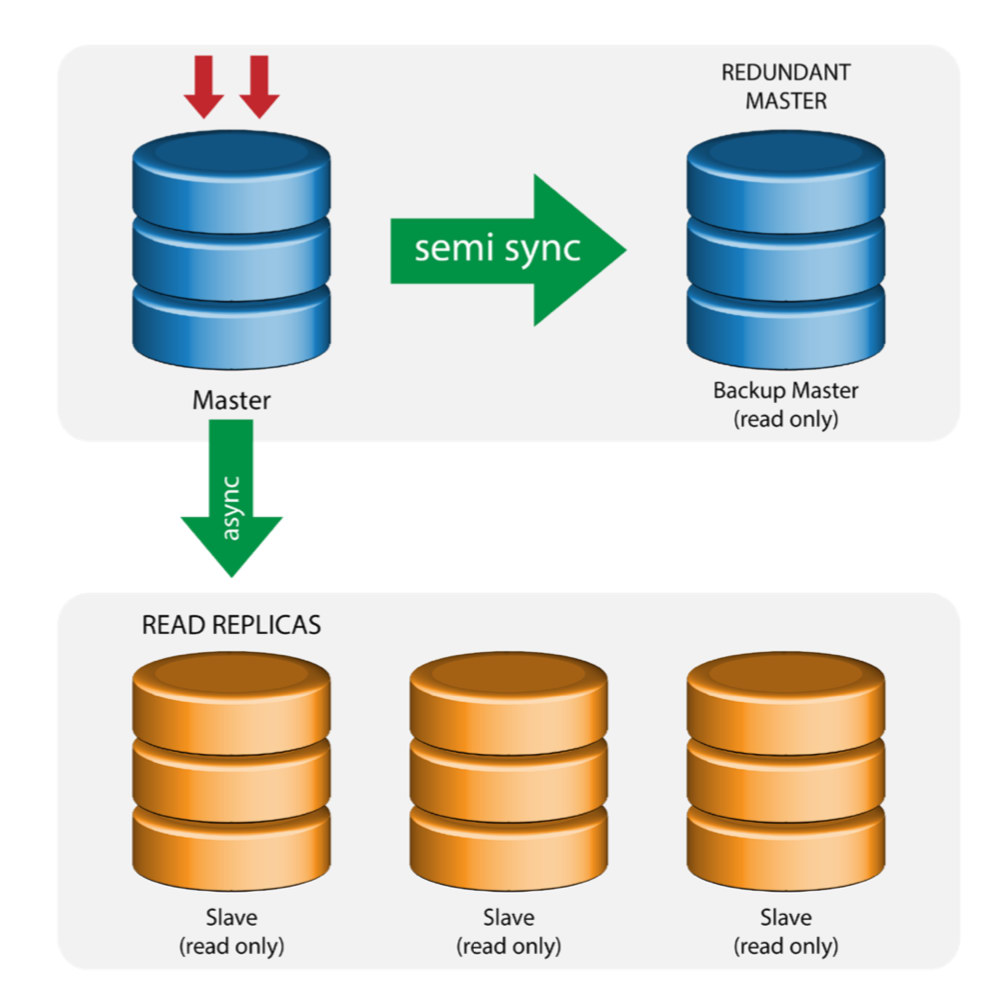
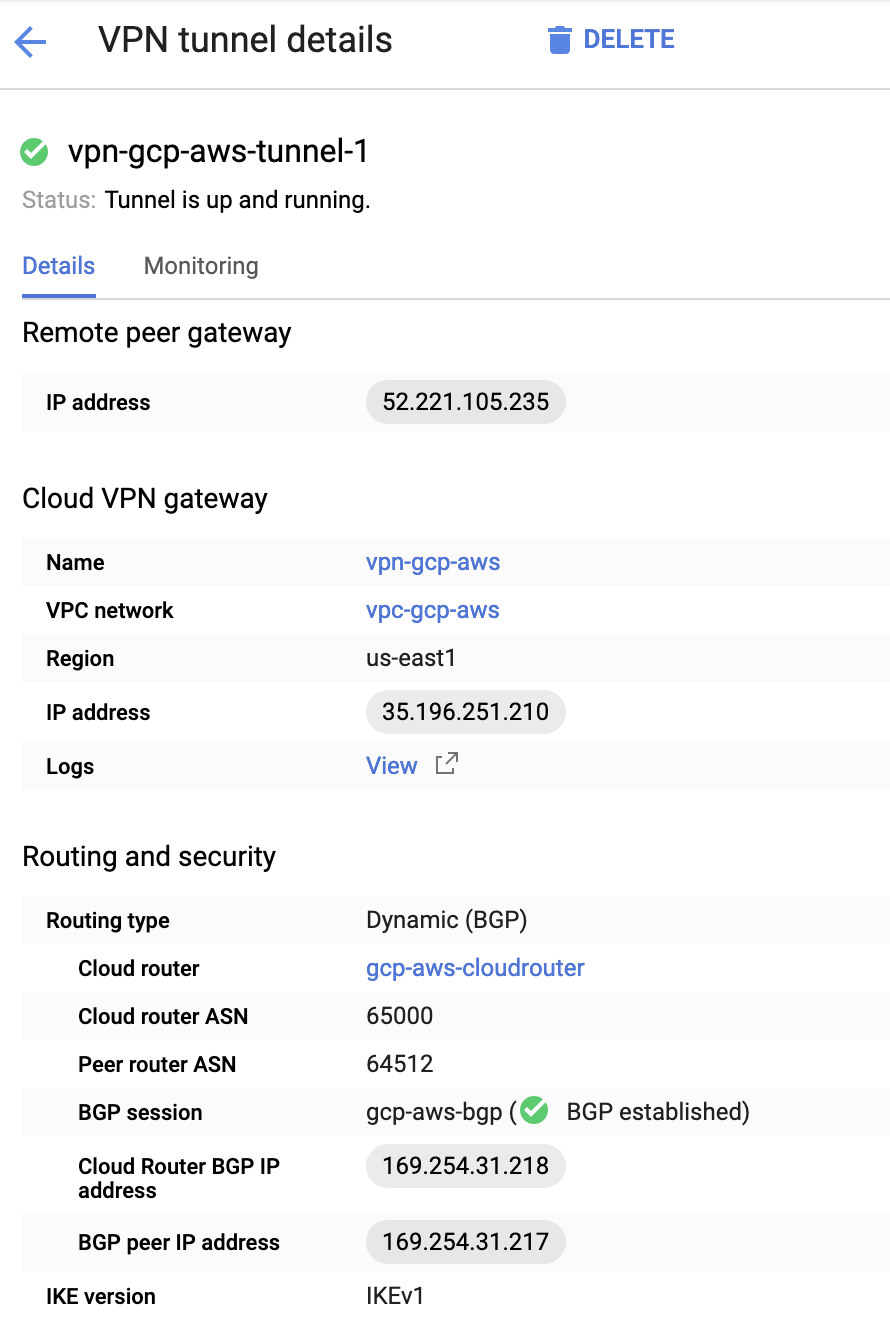
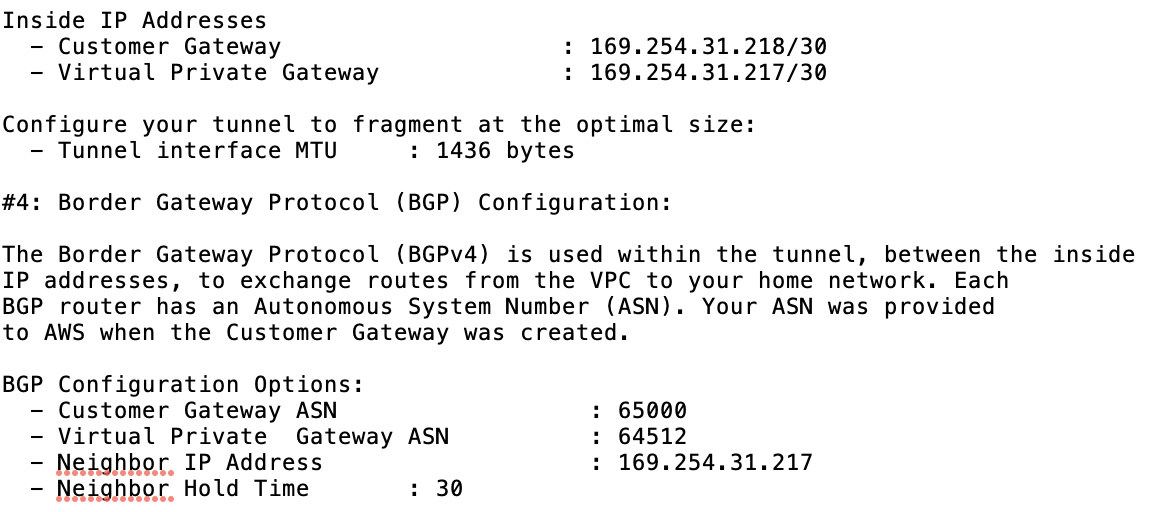
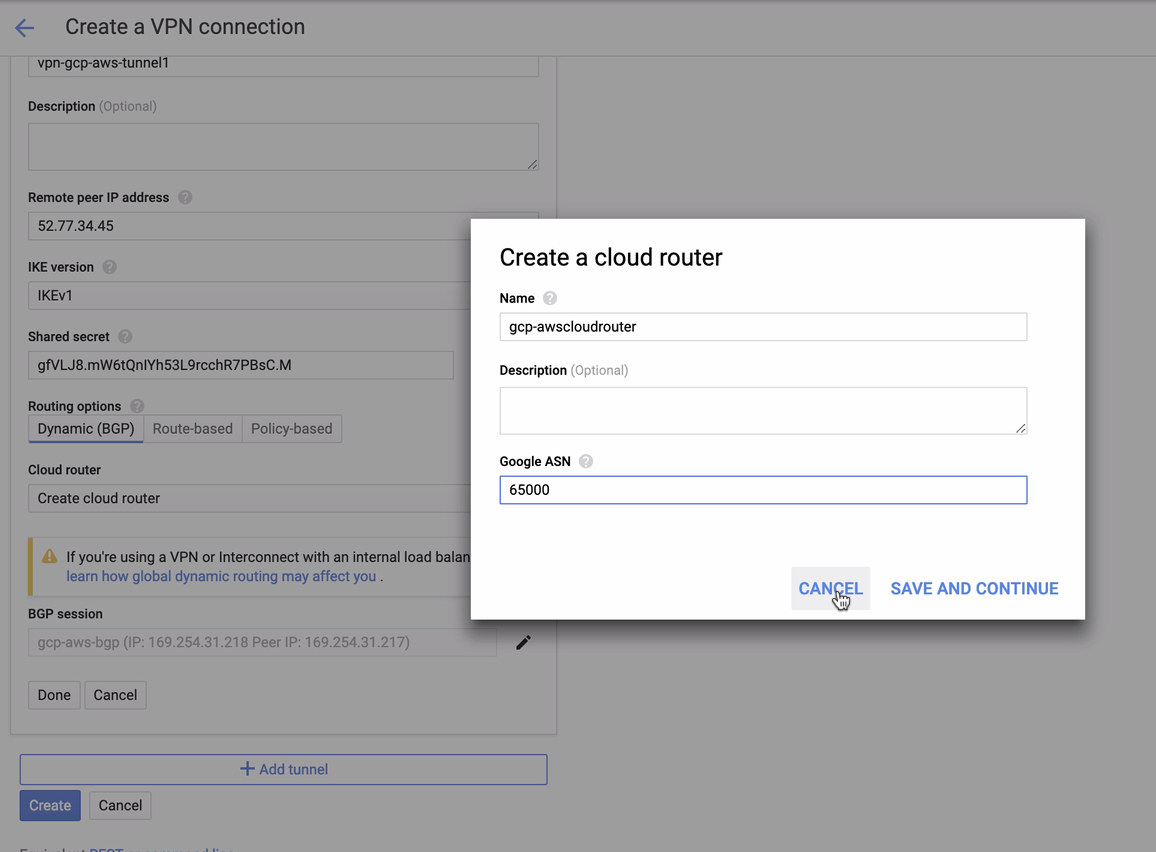
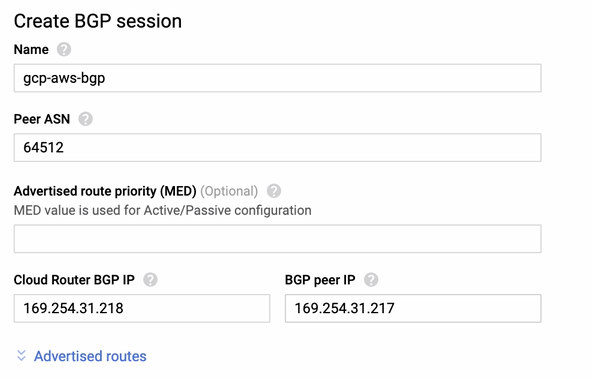
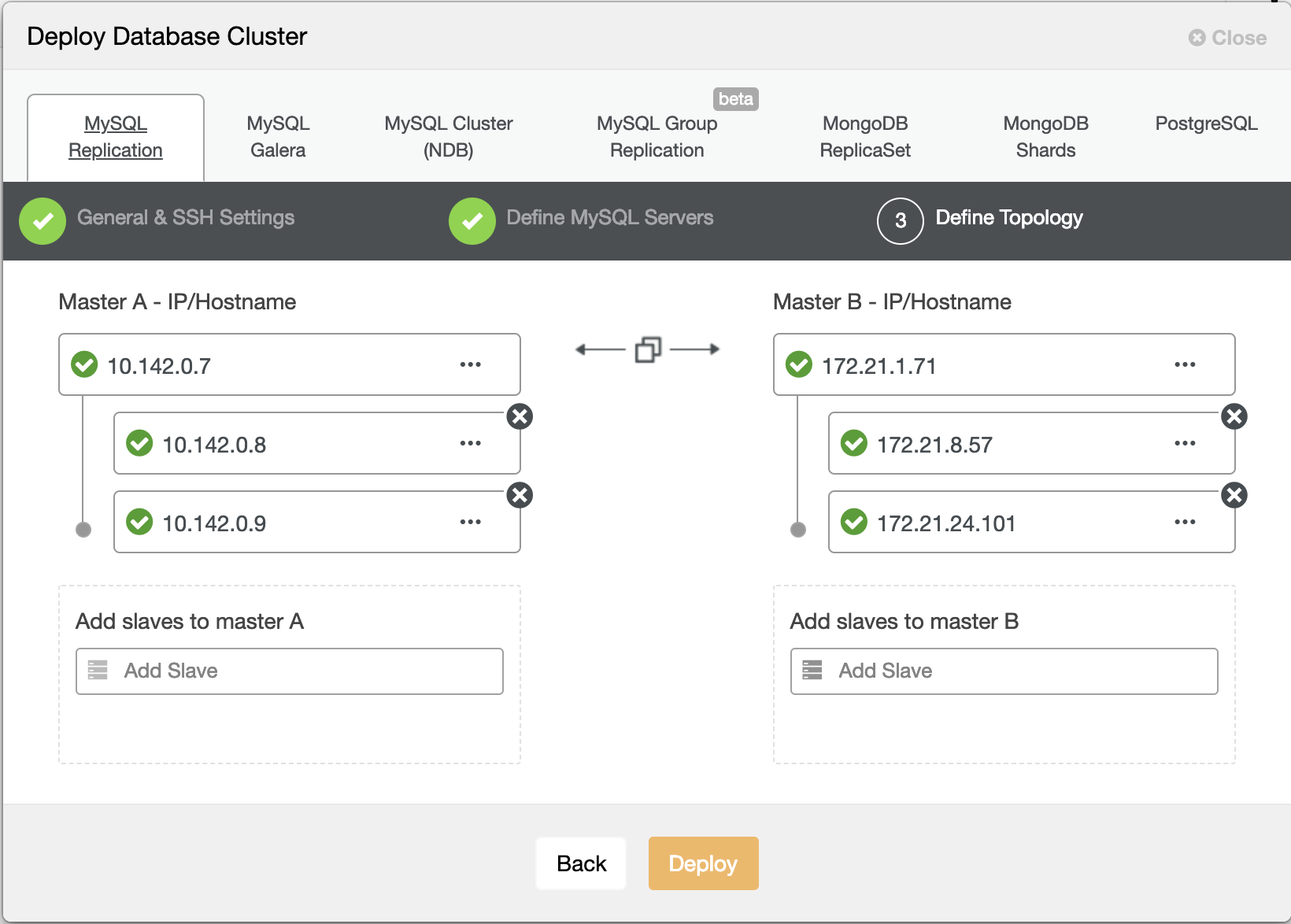
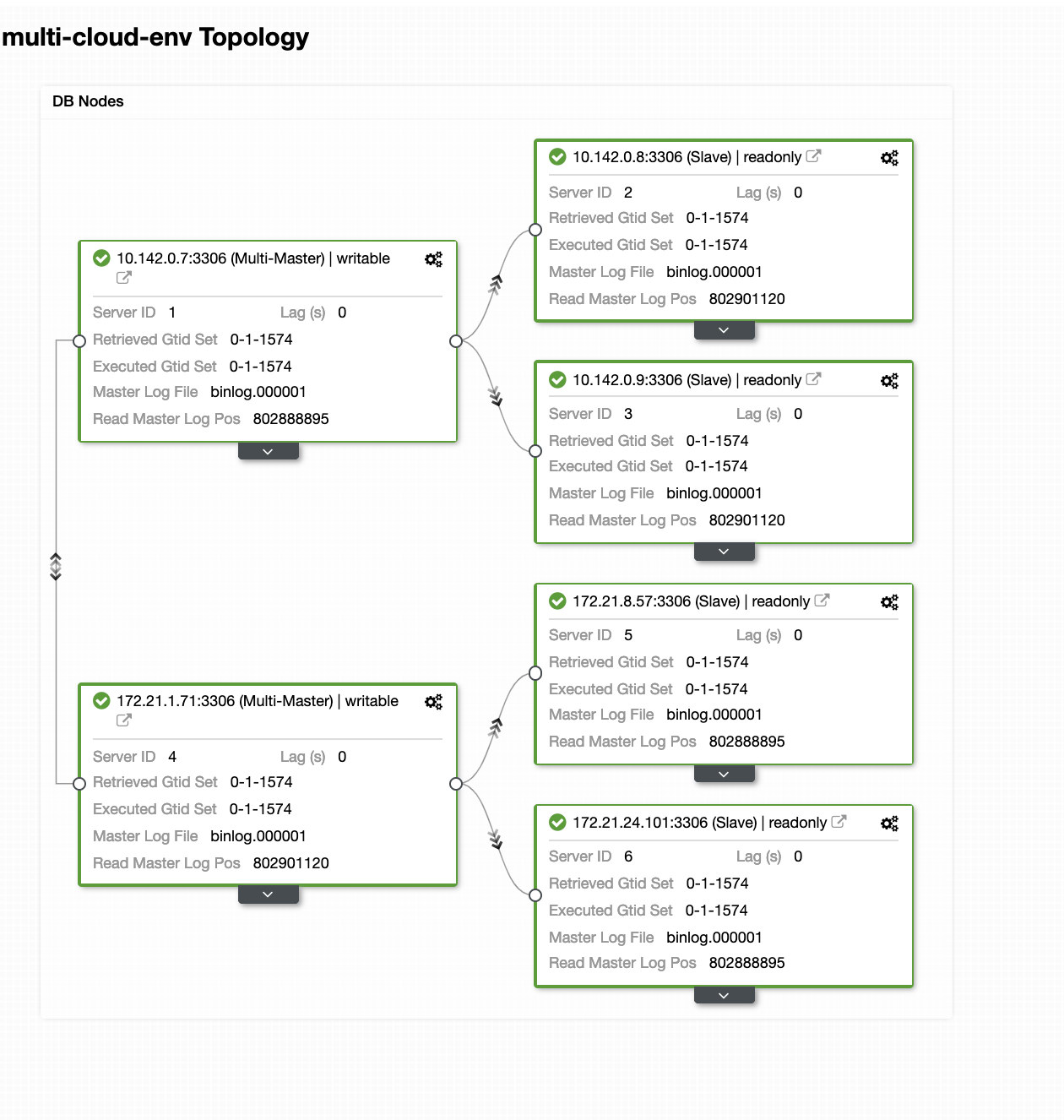
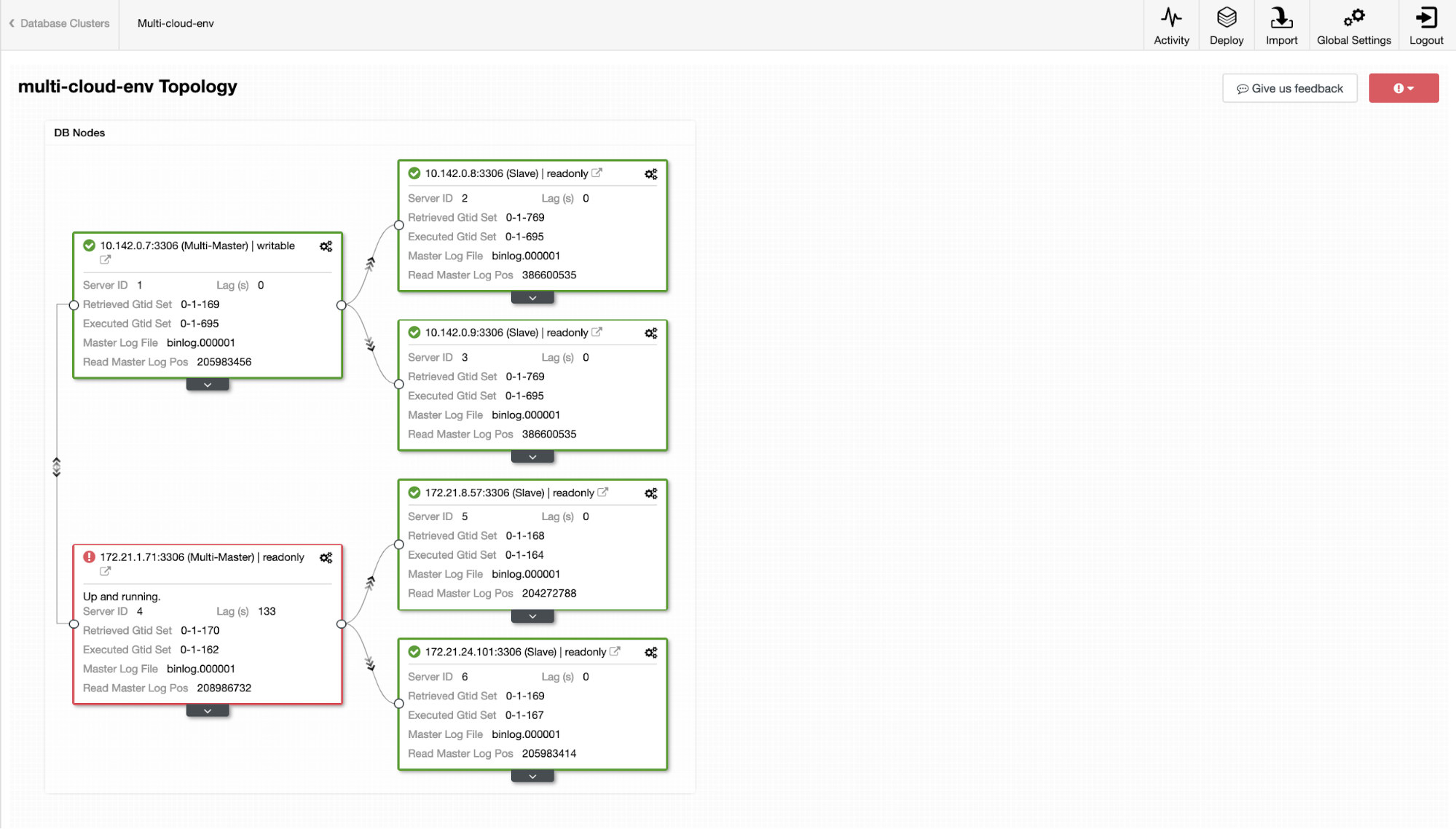
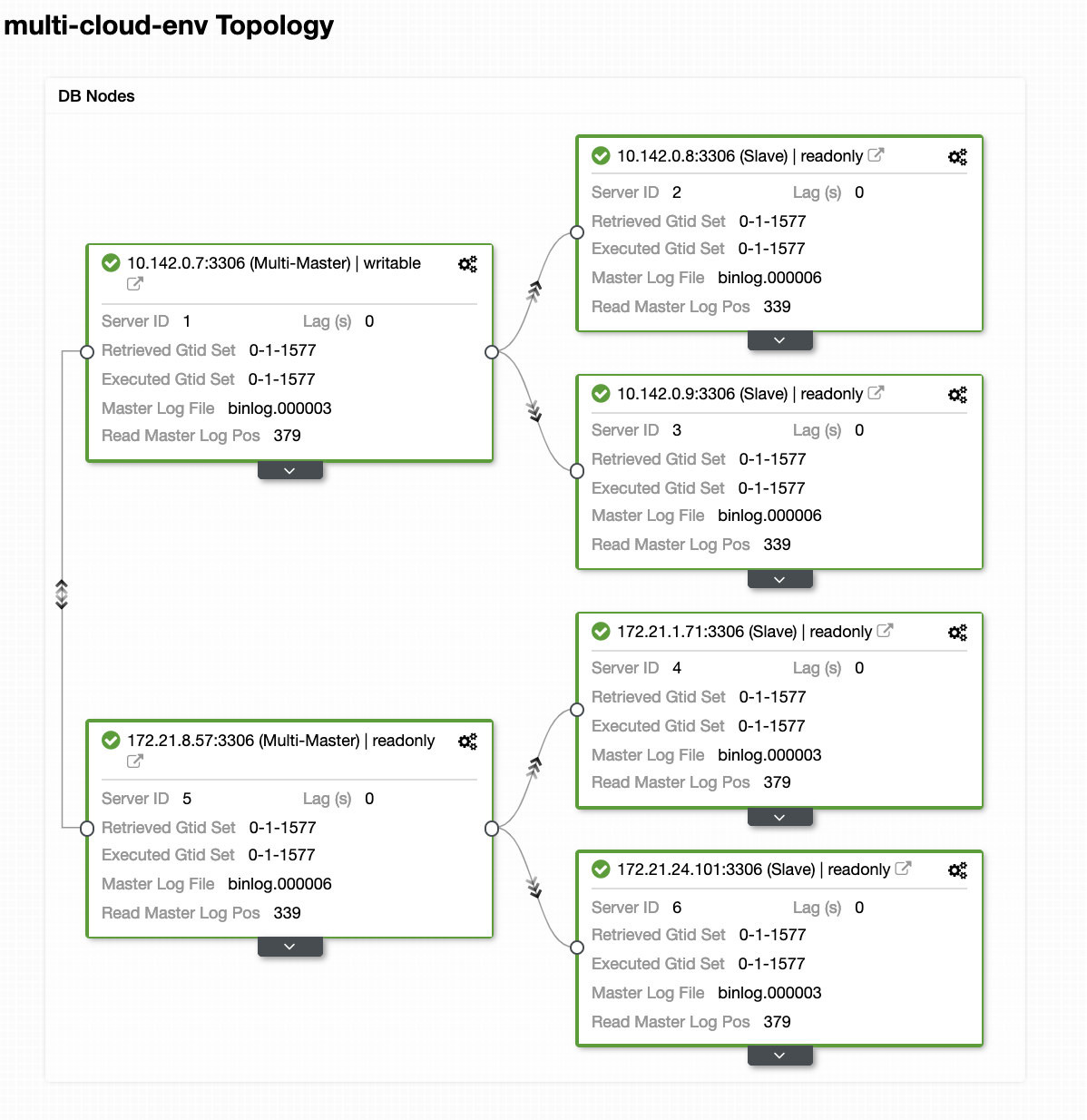
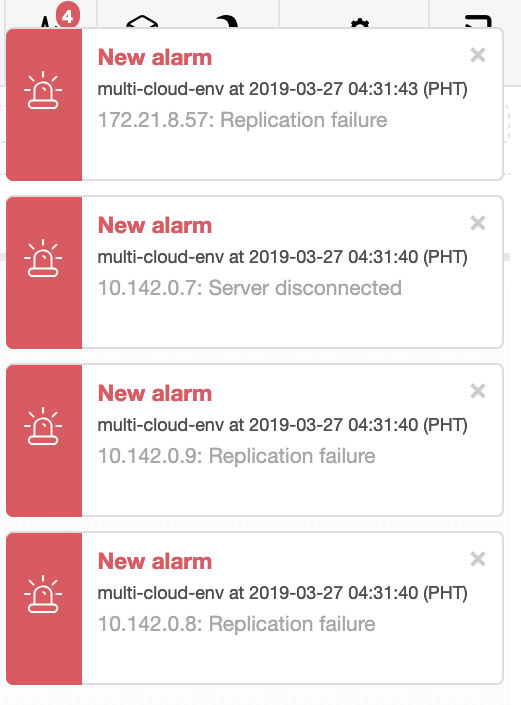
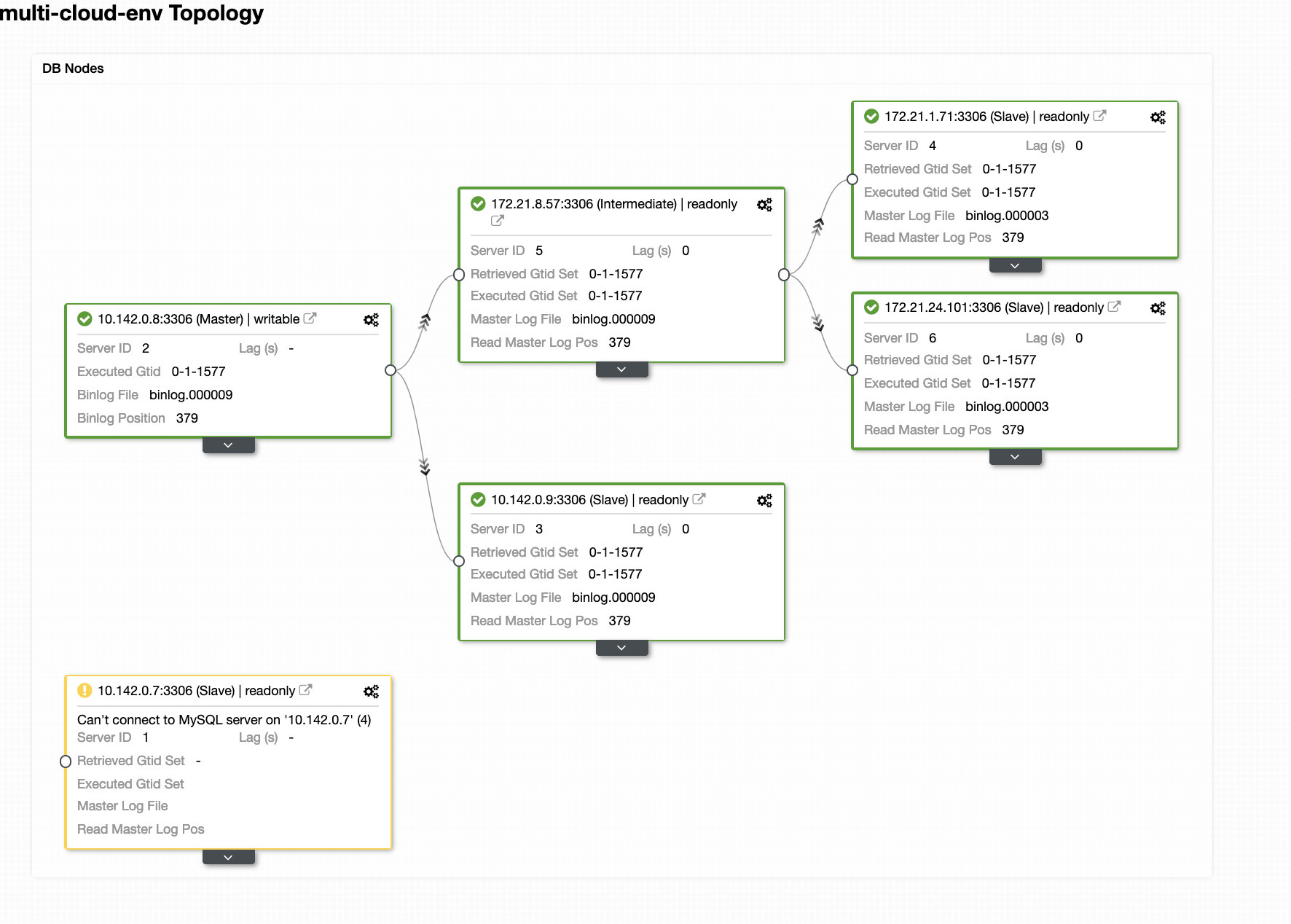
In a busy database environment with larger size databases, the need for real-time data replication is a common occurrence. Applications often need the production data to be replicated in real-time to remote sites for analytics and other critical business operations needs.
DBAs also need to ensure that the data is replicated continuously to the remote sites to meet various requirements. These requirements, though, may not always be to replicate the whole database; there can also be a need to replicate only a subset of the data (like a Table or set of Tables or data from multiple tables using an SQL for analytics, reporting etc.)
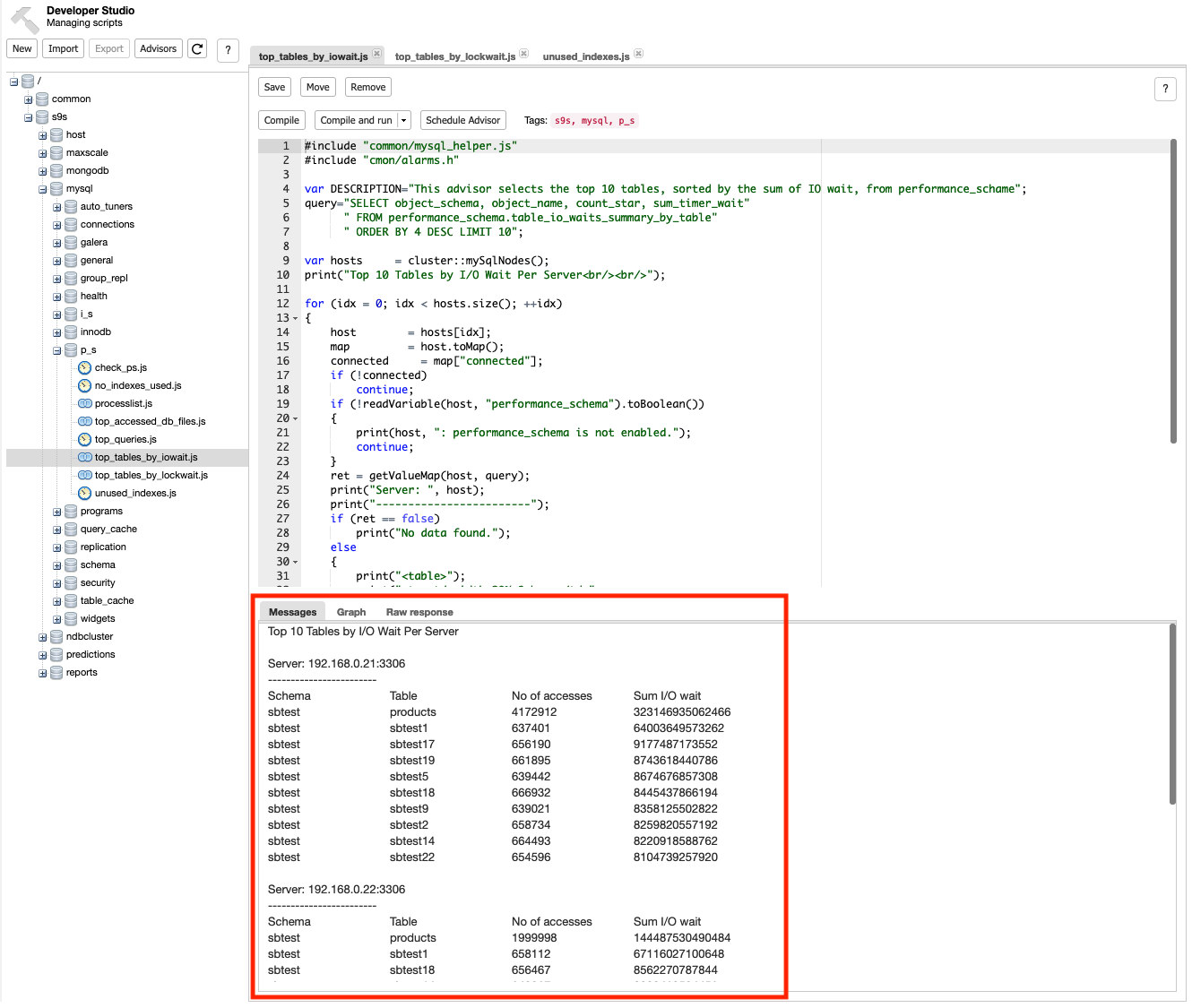
In this blog, we will focus on how to replicate tables to remote databases in real-time.
What is Table-Level Replication?
Table-level replication is the mechanism of replicating the data of a specific table or set of tables from one database (source) to another database (target) hosted remotely in a distributed environment. Table level replication ensures table data is distributed continuously and remains consistent across replicated (target) sites.
Why Use Table-Level Replication?
Table level replication is an essential need in larger, complex, highly distributed environments. In my experience, there was always a need to replicate a set of tables from a production database to a data warehousing for reporting purposes. The data has to be replicated continuously to ensure reports are getting the latest data. In critical environments, staleness of the data cannot be tolerated, so, the data changes happening on production must be replicated immediately to the target site. This can be a real challenge for DBA’s having to forecast various factors to ensure an efficient and smooth table replication.
Let us look at some requirements that table-level replication solves:
- The reports can run on a database in an environment other than production, like data warehousing
- A distributed database environment with distributed applications extracting data from multiple sites. In case of distributed web or mobile applications, the copy of the same data should be available at multiple locations to serve various application needs for which, table-level replication could be a good solution
- Payroll applications needing the data from various databases located at different geographically distributed data-centers or cloud instances to be available at a centralized database
Various Factors Impacting Table-Level Replication - What to Look For
As we mentioned above, DBAs need to take into consideration a variety of real-time components and factors to design and implement an effective table-level replication system.
Table Structure
The type of data table is accommodating has a great impact on replication performance. If the table is accommodating a BYTEA column with larger size binary data, then, the replication performance can take a hit. The impact of replication on network, CPU and Disk must be assessed carefully.
Data Size
If the table to be migrated is too big, then, the initial data migration would take up resources and time, DBAs must ensure the production database is not impacted.
Infrastructure Resources
Infrastructure must be adequately resourced to ensure a reliable and stable performing replication system can be built. What infrastructure components must be considered?
CPUs
Data replication relies heavily on CPUs. When replicating from production, CPUs must not get exhausted which can impact the production performance.
Network
It is critical for replication performance. Network latency between Source and Target database(s) must be assessed by stress-testing to ensure there is enough bandwidth for the replication to be faster. Also, the same network could be used up by other processes or applications. So, capacity planning must be done here.
Memory
There must be adequate memory available to ensure enough data is cached for faster replication.
Source Table Updates
If the data changes on the source table are heavy, then, the replication system must have the ability to sync the changes to the remote site(s) as soon as possible. Replication will end up sending a high number of sync requests to the target database which can be resource intensive.
Type of Infrastructure (data centers or cloud) can also impact replication performance and can pose challenges. Implementing monitoring could be a challenge too. If there is a lag and certain data is missing on the target database, then, it could be difficult to monitor and it cannot be synchronous
How to Implement Table Replication
Table level replication in PostgreSQL can be implemented using a variety of external tools (commercial or open-source) which are available on the market or by using custom built data-streams.
Let us have a look at some of these tools, their features and capabilities...
Slony
Slony is one of the most popular tools used to asynchronously replicate specific individual table or tables in real-time from one PostgreSQL database to another one. This is a Perl based tool which performs trigger based replication of data changes of a table (or set of tables) from a database at one site to another. It is quite reliable and it has years of development history. Though highly reliable, being a trigger-based tool, it can become complex to manage the replication setups.
Let us look at some capabilities of Slony...
Advantages of Using Slony
- Supports master to slave or multiple slaves replication methodology which, helps enhance horizontal read scalability. In other words, slaves are not writable
- Configuring Multiple slaves to a single master is possible and also supports Cascading replication methodology
- Supports switchover and failover mechanisms
- A high number of tables can be replicated in groups, in parallel
- We can replicate between different major versions of PostgreSQL instances which makes Slony a great option for database upgrades
- Simple to install
Disadvantages of Using Slony
- Does not support DDL replication
- Certain schema changes can break the replication
- Replication events are logged within the database in Slony specific log tables which can pose a maintenance overhead.
- If a huge number of tables with large data sets are to be replicated, then, performance and maintenance could pose serious challenges
- Being a trigger based replication, the performance can be affected
Bucardo
Bucardo is another open-source perl-based replication system for PostgreSQL which supports asynchronous replication of specific Table data between two or more PostgreSQL instances. What makes Bucardo different from Slony is that it also supports multi-master replication.
Let us look at different types of replication mechanisms bucardo helps implement...
- Multi-master replication: Tables can be replicated in both directions between two or more PostgreSQL instances and the transactional data will be synced bi-directionally
- Master-slave: The data from tables in master will be replicated to slave asynchronously and slave is available for reading operations
- Full copy mode (Master-slave): Bucardo -/replicate the entire data from the master to the slave node by deleting all the data from the slave
Advantages of Using Bucardo
- Simple to install
- Supports multi-master, master-slave and full copy replication modes
- It can be used to upgrade databases
- Replication can be done between different PostgreSQL versions
Disadvantages of Using Bucardo
- Being a trigger-based replication, the performance can be a challenge
- The schema changes like DDLs can break the replication
- Replicating a high number of tables can pose maintenance overhead
- The infrastructure resources must be optimized for good performing replication, otherwise, the consistency cannot be achieved.
PostgreSQL Logical Replication
Logical replication is a revolutionary built-in feature of PostgreSQL which helps to replicate individual tables via WAL records. Being a WAL based replication (similar to Streaming Replication) pg logical stands out when compared to other table replication tools. Replicating data via WAL records is always the most reliable and performant way to replicating data on the network. Almost all the tools in the market provide trigger-based replication except Logical Replication.
Advantages of Using PostgreSQL Logical Replication
- The best option when you wish to replication a single Table or set of tables
- It is a good option If the requirement is to migrate specific tables from various databases to one single database (like data warehousing or reporting databases) for reporting or analytical purposes
- No hassle of triggers
Disadvantages of Using PostgreSQL Logical Replication
- Mis-management of WAL files / WAL archive files can pose challenges to Logical Replication
- We cannot replicate tables without Primary or Unique keys
- DDLs and TRUNCATE are not replicated
- Replication Lag could increase if the WALs are removed. This means, the replication and WAL management must complement each other to ensure the replication does not break
- Large objects cannot be replicated
Here are some more resources to help you better understand PostgreSQL Logical Replication and the differences between it and streaming replication.
Foreign Data Wrappers
While Foreign Data Wrappers do not actually replicate the data, I wanted to highlight this feature of PostgreSQL because it can help DBAs achieve something similar to replication without actually replicating the data. This means the data is not replicated from source to target and the data can be accessed by applications from the target database. The target database only has a table structure with a link containing Host and database details of the source table and when application query the target table, then, the data is pulled over from the source database to the target database similar to Database Links. If FDWs can help, then, you can entirely avoid the overhead of replicating the data over the network. Many times we do get into a situation where reports can be executed on a remote target database without needing the data to be present physically.
FDWs are a great option in the following situations -
- If you have small and static tables in the source database, then, it is not really worth replicating the data over
- Can be really beneficial, If you have really big tables in the source database and you are running aggregate queries on the target database.
Advantages of Using Foreign Data Wrappers
- Replicating data can be completely avoided which can save time and resources
- Simple to implement
- Data pulled over is always the latest
- No maintenance over head
Disadvantages of Using Foreign Data Wrappers
- Structural changes on the source table can impact application functionality on the target database
- Heavily relies on the network and can have a significant network overhead depending on the type of reports being run
- Performance overhead is expected when the queries are executed a several number of times as each time query is executed, the data must be pulled over the network from the source database and also can pose performance overhead on the source database
- Any load on the source can impact the performance of applications on the target database
Conclusion
- Replicating tables can serve various critical purposes for business
- Can support distributed parallel querying in distributed environments
- Implementing synchronous is nearly impossible
- Infrastructure must be adequately capacitated which involves costs
- A great option to build an integrated centralized database for reporting and analytical purposes