There are multiple ways of deploying a database. You can install it by hand, you can rely on the widely available infrastructure orchestration tools like Ansible, Chef, Puppet or Salt. Those tools are very popular and it is quite easy to find scripts, recipes, playbooks, you name it, which will help you automate the installation of a database cluster. There are also more specialized database automation platforms, like ClusterControl, which can also be used to automated deployment. What would be the best way of deploying your cluster? How much time you will actually need to deploy it?
First, let us clarify what we want to do. Let’s assume we will be deploying Percona XtraDB Cluster 5.7. It will consist of three nodes and for that we will use three Vagrant virtual machines running Ubuntu 16.04 (bento/ubuntu-16.04 image). We will attempt to deploy a cluster manually, then using Ansible and ClusterControl. Let’s see how the results will look like.
Manual Deployment
Repository Setup - 1 minute, 45 seconds.
First of all, we have to configure Percona repositories on all Ubuntu nodes. Quick google search, ssh into the virtual machines and running required commands takes 1m45s
We found the following page with instructions:
https://www.percona.com/doc/percona-repo-config/percona-release.html
and we executed steps described in “DEB-BASED GNU/LINUX DISTRIBUTIONS” section. We also ran apt update, to refresh apt’s cache.
Installing PXC Nodes - 2 minutes 45 seconds
This step basically consists of executing:
root@vagrant:~# apt install percona-xtradb-cluster-5.7
The rest is mostly dependent on your internet connection speed as packages are being downloaded. Your input will also be needed (you’ll be passing a password for the superuser) so it is not unattended installation. When everything is done, you will end up with three running Percona XtraDB Cluster nodes:
root 15488 0.0 0.2 4504 1788 ? S 10:12 0:00 /bin/sh /usr/bin/mysqld_safe
mysql 15847 0.3 28.3 1339576 215084 ? Sl 10:12 0:00 \_ /usr/sbin/mysqld --basedir=/usr --datadir=/var/lib/mysql --plugin-dir=/usr/lib/mysql/plugin --user=mysql --wsrep-provider=/usr/lib/galera3/libgalera_smm.so --log-error=/var/log/mysqld.log --pid-file=/var/run/mysqld/mysqld.pid --socket=/var/run/mysqld/mysqld.sock --wsrep_start_position=00000000-0000-0000-0000-000000000000:-1
Configuring PXC nodes - 3 minutes, 25 seconds
Here starts the tricky part. It is really hard to quantify experience and how much time one would need to actually understand what is needed to be done. What is good, google search “how to install percona xtrabdb cluster” points to Percona’s documentation, which describes how the process should look like. It still may take more or less time, depending on how familiar you are with the PXC and Galera in general. Worst case scenario you will not be aware of any additional required actions and you will connect to your PXC and start working with it, not realizing that, in fact, you have three nodes, each forming a cluster of its own.
Let’s assume we follow the recommendation from Percona and time just those steps to be executed. In short, we modified configuration files as per instructions on the Percona website, we also attempted to bootstrap the first node:
root@vagrant:~# /etc/init.d/mysql bootstrap-pxc
mysqld: [ERROR] Found option without preceding group in config file /etc/mysql/my.cnf at line 10!
mysqld: [ERROR] Fatal error in defaults handling. Program aborted!
mysqld: [ERROR] Found option without preceding group in config file /etc/mysql/my.cnf at line 10!
mysqld: [ERROR] Fatal error in defaults handling. Program aborted!
mysqld: [ERROR] Found option without preceding group in config file /etc/mysql/my.cnf at line 10!
mysqld: [ERROR] Fatal error in defaults handling. Program aborted!
mysqld: [ERROR] Found option without preceding group in config file /etc/mysql/my.cnf at line 10!
mysqld: [ERROR] Fatal error in defaults handling. Program aborted!
* Bootstrapping Percona XtraDB Cluster database server mysqld ^C
This did not look correct. Unfortunately, instructions weren’t crystal clear. Again, if you don’t know what is going on, you will spend more time trying to understand what happened. Luckily, stackoverflow.com comes very helpful (although not the first response on the list that we got) and you should realise that you miss [mysqld] section header in your /etc/mysql/my.cnf file. Adding this on all nodes and repeating the bootstrap process solved the issue. In total we spent 3 minutes and 25 seconds (not including googling for the error as we noticed immediately what was the problem).
Configuring for SST, Bringing Other Nodes Into the Cluster - Starting From 8 Minutes to Infinity
The instructions on Percona web site are quite clear. Once you have one node up and running, just start remaining nodes and you will be fine. We tried that and we were unable to see more nodes joining the cluster. This is where it is virtually impossible to tell how long it will take to diagnose the issue. It took us 6-7 minutes but to be able to do it quickly you have to:
- Be familiar with how PXC configuration is structured:
root@vagrant:~# tree /etc/mysql/
/etc/mysql/
├── conf.d
│ ├── mysql.cnf
│ └── mysqldump.cnf
├── my.cnf -> /etc/alternatives/my.cnf
├── my.cnf.fallback
├── my.cnf.old
├── percona-xtradb-cluster.cnf
└── percona-xtradb-cluster.conf.d
├── client.cnf
├── mysqld.cnf
├── mysqld_safe.cnf
└── wsrep.cnf
- Know how the !include and !includedir directives work in MySQL configuration files
- Know how MySQL handles the same variables included in multiple files
- Know what to look for and be aware of configurations that would result in node bootstrapping itself to form a cluster on its own
The problem was related to the fact that instructions did not mention any file except for /etc/mysql/my.cnf where, in fact, we should have been modifying /etc/mysql/percona-xtradb-cluster.conf.d/wsrep.cnf. That file contained empty variable:
wsrep_cluster_address=gcomm://
and such configuration forces node to bootstrap as it does not have information about other nodes to join to. We set that variable in /etc/mysql/my.cnf but later wsrep.cnf file was included, overwriting our setup.
This issue might be a serious blocker for people who are not really familiar with how MySQL and Galera works, resulting even in hours if not more of debugging.
Total Installation Time - 16 minutes (If You Are MySQL DBA Like I Am)
We managed to install Percona XtraDB Cluster in 16 minutes. You have to keep in mind a couple of things - we did not tune the configuration. This is something which will require more time and knowledge. PXC node comes with some simple configuration, related mostly to binary logging and Galera writeset replication. There is no InnoDB tuning. If you are not familiar with MySQL internals, this is hours if not days of reading and familiarizing yourself with internal mechanisms. Another important thing is that this is a process you would have to re-apply for every cluster you deploy. Finally, we managed to identify the issue and solve it very fast due to our experience with Percona XtraDB Cluster and MySQL in general. Casual user will most likely spend significantly more time trying to understand what is going on and why.
Ansible Playbook
Now, on to automation with Ansible. Let’s try to find and use an ansible playbook, which we could reuse for all further deployments. Let’s see how long will it take to do that.
Configuring SSH Connectivity - 1 minute
Ansible requires SSH connectivity across all the nodes to connect and configure them. We generated a SSH key and manually distributed it across the nodes.
Finding Ansible Playbook - 2 minutes 15 seconds
The main issue here is that there are so many playbooks available out there that it is impossible to decide what’s best. As such, we decided to go with top 3 Google results and try to pick one. We decided on https://github.com/cdelgehier/ansible-role-XtraDB-Cluster as it seems to be more configurable than the remaining ones.
Cloning Repository and Installing Ansible - 30 seconds
This is quick, all we needed was to
apt install ansible git
git clone https://github.com/cdelgehier/ansible-role-XtraDB-Cluster.git
Preparing Inventory File - 1 minute 10 seconds
This step was also very simple, we created an inventory file using example from documentation. We just substituted IP addresses of the nodes to what we have configured in our environment.
Preparing a Playbook - 1 minute 45 seconds
We decided to use the most extensive example from the documentation, which includes also a bit of the configuration tuning. We prepared a correct structure for the Ansible (there was no such information in the documentation):
/root/pxcansible/
├── inventory
├── pxcplay.yml
└── roles
└── ansible-role-XtraDB-Cluster
Then we ran it but immediately we got an error:
root@vagrant:~/pxcansible# ansible-playbook pxcplay.yml
[WARNING]: provided hosts list is empty, only localhost is available
ERROR! no action detected in task
The error appears to have been in '/root/pxcansible/roles/ansible-role-XtraDB-Cluster/tasks/main.yml': line 28, column 3, but may
be elsewhere in the file depending on the exact syntax problem.
The offending line appears to be:
- name: "Include {{ ansible_distribution }} tasks"
^ here
We could be wrong, but this one looks like it might be an issue with
missing quotes. Always quote template expression brackets when they
start a value. For instance:
with_items:
- {{ foo }}
Should be written as:
with_items:
- "{{ foo }}"
This took 1 minute and 45 seconds.
Fixing the Playbook Syntax Issue - 3 minutes 25 seconds
The error was misleading but the general rule of thumb is to try more recent Ansible version, which we did. We googled and found good instructions on Ansible website. Next attempt to run the playbook also failed:
TASK [ansible-role-XtraDB-Cluster : Delete anonymous connections] *****************************************************************************************************************************************************************************************************************
fatal: [node2]: FAILED! => {"changed": false, "msg": "The PyMySQL (Python 2.7 and Python 3.X) or MySQL-python (Python 2.X) module is required."}
fatal: [node3]: FAILED! => {"changed": false, "msg": "The PyMySQL (Python 2.7 and Python 3.X) or MySQL-python (Python 2.X) module is required."}
fatal: [node1]: FAILED! => {"changed": false, "msg": "The PyMySQL (Python 2.7 and Python 3.X) or MySQL-python (Python 2.X) module is required."}
Setting up new Ansible version and running the playbook up to this error took 3 minutes and 25 seconds.
Fixing the Missing Python Module - 3 minutes 20 seconds
Apparently, the role we used did not take care of its prerequisites and a Python module was missing for connecting to and securing the Galera cluster. We first tried to install MySQL-python via pip but it became apparent that it will take more time as it required mysql_config:
root@vagrant:~# pip install MySQL-python
Collecting MySQL-python
Downloading https://files.pythonhosted.org/packages/a5/e9/51b544da85a36a68debe7a7091f068d802fc515a3a202652828c73453cad/MySQL-python-1.2.5.zip (108kB)
100% |████████████████████████████████| 112kB 278kB/s
Complete output from command python setup.py egg_info:
sh: 1: mysql_config: not found
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/tmp/pip-build-zzwUtq/MySQL-python/setup.py", line 17, in <module>
metadata, options = get_config()
File "/tmp/pip-build-zzwUtq/MySQL-python/setup_posix.py", line 43, in get_config
libs = mysql_config("libs_r")
File "/tmp/pip-build-zzwUtq/MySQL-python/setup_posix.py", line 25, in mysql_config
raise EnvironmentError("%s not found" % (mysql_config.path,))
EnvironmentError: mysql_config not found
----------------------------------------
Command "python setup.py egg_info" failed with error code 1 in /tmp/pip-build-zzwUtq/MySQL-python/
That is provided by MySQL development libraries so we would have to install them manually, which was pretty much pointless. We decided to go with PyMySQL, which did not require other packages to install. This brought us to another issue:
TASK [ansible-role-XtraDB-Cluster : Delete anonymous connections] *****************************************************************************************************************************************************************************************************************
fatal: [node3]: FAILED! => {"changed": false, "msg": "unable to connect to database, check login_user and login_password are correct or /root/.my.cnf has the credentials. Exception message: (1698, u\"Access denied for user 'root'@'localhost'\")"}
fatal: [node2]: FAILED! => {"changed": false, "msg": "unable to connect to database, check login_user and login_password are correct or /root/.my.cnf has the credentials. Exception message: (1698, u\"Access denied for user 'root'@'localhost'\")"}
fatal: [node1]: FAILED! => {"changed": false, "msg": "unable to connect to database, check login_user and login_password are correct or /root/.my.cnf has the credentials. Exception message: (1698, u\"Access denied for user 'root'@'localhost'\")"}
to retry, use: --limit @/root/pxcansible/pxcplay.retry
Up to this point we spent 3 minutes and 20 seconds.
Fixing “Access Denied” Error - 18 minutes 55 seconds
As per error, we did ensure that MySQL config is prepared correctly and that it included correct user and password to connect to the database. This, unfortunately, did not work as expected. We did investigate further and found that the role did not create root user properly, even though it marked the step as completed. We did a short investigation but decided to make the manual fix instead of trying to debug the playbook, which would take way more time than the steps which we did. We just created manually users root@127.0.0.1 and root@localhost with correct passwords. This allowed us to pass this step and onto another error:
TASK [ansible-role-XtraDB-Cluster : Start the master node] ************************************************************************************************************************************************************************************************************************
skipping: [node1]
skipping: [node2]
skipping: [node3]
TASK [ansible-role-XtraDB-Cluster : Start the master node] ************************************************************************************************************************************************************************************************************************
skipping: [node1]
skipping: [node2]
skipping: [node3]
TASK [ansible-role-XtraDB-Cluster : Create SST user] ******************************************************************************************************************************************************************************************************************************
skipping: [node1]
skipping: [node2]
skipping: [node3]
TASK [ansible-role-XtraDB-Cluster : Start the slave nodes] ************************************************************************************************************************************************************************************************************************
fatal: [node3]: FAILED! => {"changed": false, "msg": "Unable to start service mysql: Job for mysql.service failed because the control process exited with error code. See \"systemctl status mysql.service\" and \"journalctl -xe\" for details.\n"}
fatal: [node2]: FAILED! => {"changed": false, "msg": "Unable to start service mysql: Job for mysql.service failed because the control process exited with error code. See \"systemctl status mysql.service\" and \"journalctl -xe\" for details.\n"}
fatal: [node1]: FAILED! => {"changed": false, "msg": "Unable to start service mysql: Job for mysql.service failed because the control process exited with error code. See \"systemctl status mysql.service\" and \"journalctl -xe\" for details.\n"}
to retry, use: --limit @/root/pxcansible/pxcplay.retry
For this section we spent 18 minutes and 55 seconds.
Fixing “Start the Slave Nodes” Issue (part 1) - 7 minutes 40 seconds
We tried a couple of things to solve this problem. We tried to specify node using its name, we tried to switch group names, nothing solved the issue. We decided to clean up the environment using the script provided in the documentation and start from scratch. It did not clean it but just made things even worse. After 7 minutes and 40 seconds we decided to wipe out the virtual machines, recreate the environment and start from scratch hoping that when we add the Python dependencies, this will solve our issue.
Fixing “Start the Slave Nodes” Issue (part 2) - 13 minutes 15 seconds
Unfortunately, setting up Python prerequisites did not help at all. We decided to finish the process manually, bootstrapping the first node and then configuring SST user and starting remaining slaves. This completed the “automated” setup and it took us 13 minutes and 15 seconds to debug and then finally accept that it will not work like the playbook designer expected.
Further Debugging - 10 minutes 45 seconds
We did not stop there and decided that we’ll try one more thing. Instead of relying on Ansible variables we just put the IP of one of the nodes as the master node. This solved that part of the problem and we ended up with:
TASK [ansible-role-XtraDB-Cluster : Create SST user] ******************************************************************************************************************************************************************************************************************************
skipping: [node2]
skipping: [node3]
fatal: [node1]: FAILED! => {"changed": false, "msg": "unable to connect to database, check login_user and login_password are correct or /root/.my.cnf has the credentials. Exception message: (1045, u\"Access denied for user 'root'@'::1' (using password: YES)\")"}
This was the end of our attempts - we tried to add this user but it did not work correctly through the ansible playbook while we could use IPv6 localhost address to connect to when using MySQL client.
Total Installation Time - Unknown (Automated Installation Failed)
In total we spent 64 minutes and we still haven’t managed to get things going automatically. The remaining problems are root password creation which doesn’t seem to work and then getting the Galera Cluster started (SST user issue). It is hard to tell how long will it take to debug it further. It is sure possible - it is just hard to quantify because it really depends on the experience with Ansible and MySQL. It is definitely not something anyone can just download, configure and run. Well, maybe another playbook would have worked differently? It is possible, but it may as well result in different issues. Ok, so there is a learning curve to climb and debugging to make but then, when you are all set, you will just run a script. Well, that’s sort of true. As long as changes introduced by the maintainer won’t break something you depend on or new Ansible version will break the playbook or the maintainer will just forget about the project and stop developing it (for the role that we used there’s quite useful pull request waiting already for almost a year, which might be able to solve the Python dependency issue - it has not been merged). Unless you accept that you will have to maintain this code, you cannot really rely on it being 100% accurate and working in your environment, especially given that the original developer has no incentives in keeping the code up to date. Also, what about other versions? You cannot use this particular playbook to install PXC 5.6 or any MariaDB version. Sure, there are other playbooks you can find. Will they work better or maybe you’ll spend another bunch of hours trying to make them to work?
Single Console for Your Entire Database Infrastructure
Find out what else is new in ClusterControl
ClusterControl
Finally, let’s take a look at how ClusterControl can be used to deploy Percona XtraDB Cluster.
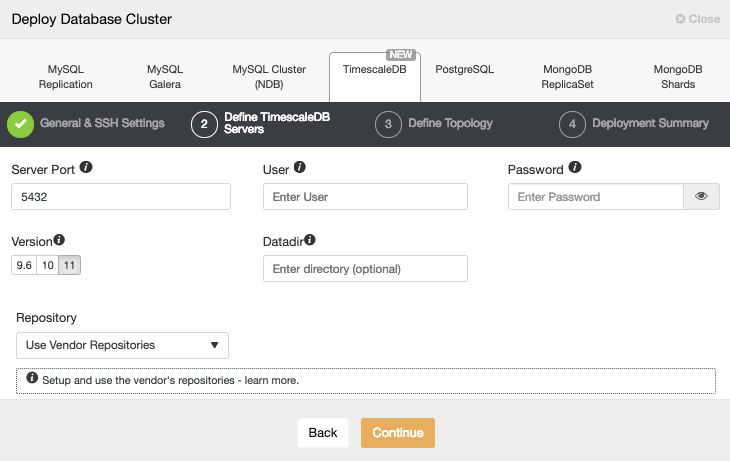
Configuring SSH Connectivity - 1 minute
ClusterControl requires SSH connectivity across all the nodes to connect and configure them. We generated a SSH key and manually distributed it across the nodes.
Setting Up ClusterControl - 3 minutes 15 seconds
Quick search “ClusterControl install” pointed us to relevant ClusterControl documentation page. We were looking for a “simpler way to install ClusterControl” therefore we followed the link and found following instructions.
Downloading the script and running it took 3 minutes and 15 seconds, we had to take some actions while installation proceeded so it is not unattended installation.
Logging Into UI and Deployment Start - 1 minute 10 seconds
We pointed our browser to the IP of ClusterControl node.
We passed the required contact information and we were presented with the Welcome screen:
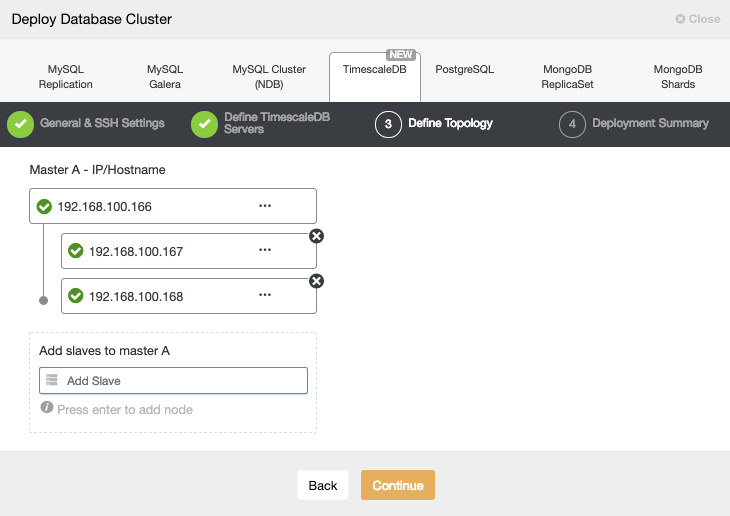
Next step - we picked the deployment option.
We had to pass SSH connectivity details.
We also decided on the vendor, version, password and hosts to use. This whole process took 1 minute and 10 seconds.
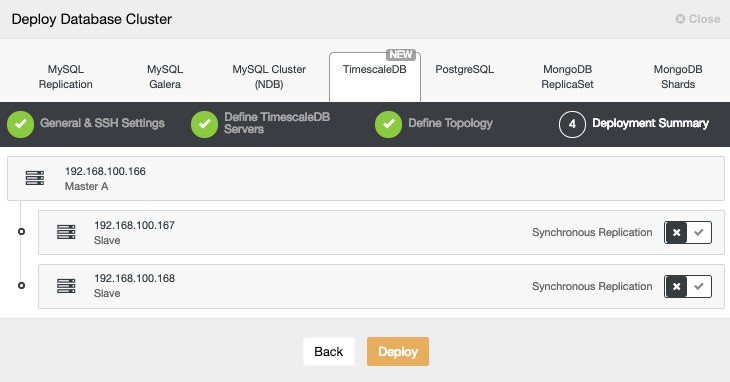
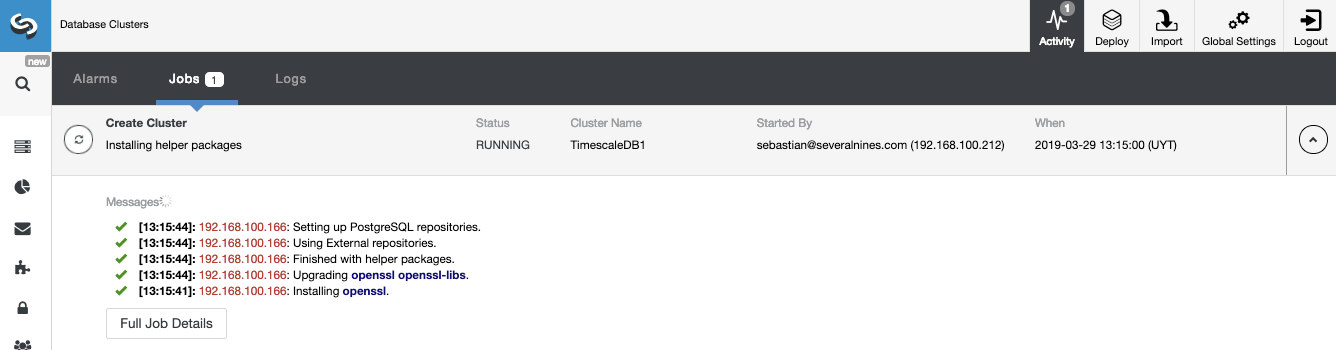
Percona XtraDB Cluster Deployment - 12 minutes 5 seconds
The only thing left was to wait for ClusterControl to finish the deployment. After 12 minutes and 5 seconds the cluster was ready:
Total Installation Time - 17 minutes 30 seconds
We managed to deploy ClusterControl and then PXC cluster using ClusterControl in 17 minutes and 30 seconds. The PXC deployment itself took 12 minutes and 5 seconds. At the end we have a working cluster, deployed according to the best practices. ClusterControl also ensures that the configuration of the cluster makes sense. In short, even if you don't really know anything about MySQL or Galera Cluster, you can have a production-ready cluster deployed in a couple of minutes. ClusterControl is not just a deployment tool, it is also management platform - makes things even easier for people not experienced with MySQL and Galera to identify performance problems (through advisors) and do management actions (scaling the cluster up and down, running backups, creating asynchronous slaves to Galera). What is important, ClusterControl will always be maintained and can be used to deploy all MySQL flavors (and not only MySQL/MariaDB, it also supports TimeScaleDB, PostgreSQL and MongoDB). It also worked out of the box, something which cannot be said about other methods we tested.
If you would like to experience the same, you can download ClusterControl for free. Let us know how you liked it.