Are you still struggling to pick the best open source database software for your organisation? You would have penned down a must-have feature list right from deploying, managing, and monitoring a database but finding the best fit?... still not there.
There are many software vendors out there trying their best to offer a variety of combinations of features to manage the open-source databases, so it would be wise to get an insight on the current happenings around this space before making any decision.
Recently Percona conducted a survey on 750 respondents from small, medium, and large companies to try to understand how they have managed their open source database environments. The survey results have led to interesting findings to understand the trends in open source database adoption by the open source community.
This blog walks you through important points on open source database features, leading technologies, adoption factors, and concerns evaluated by those organisations.
Multiple Open Source Environments
Many companies now have multiple databases on multiple platforms across different locations, to keep up with the rapid needs and changes in their business. The need for multiple database instances often increases as the data volume increases. On average, over half of the open source community uses at least 25 instances for this purpose.

73% of relational database users, shows that the relational database is still the market preference over the multiple-model databases like time-Series, graph, wide column, and other niche database technologies.
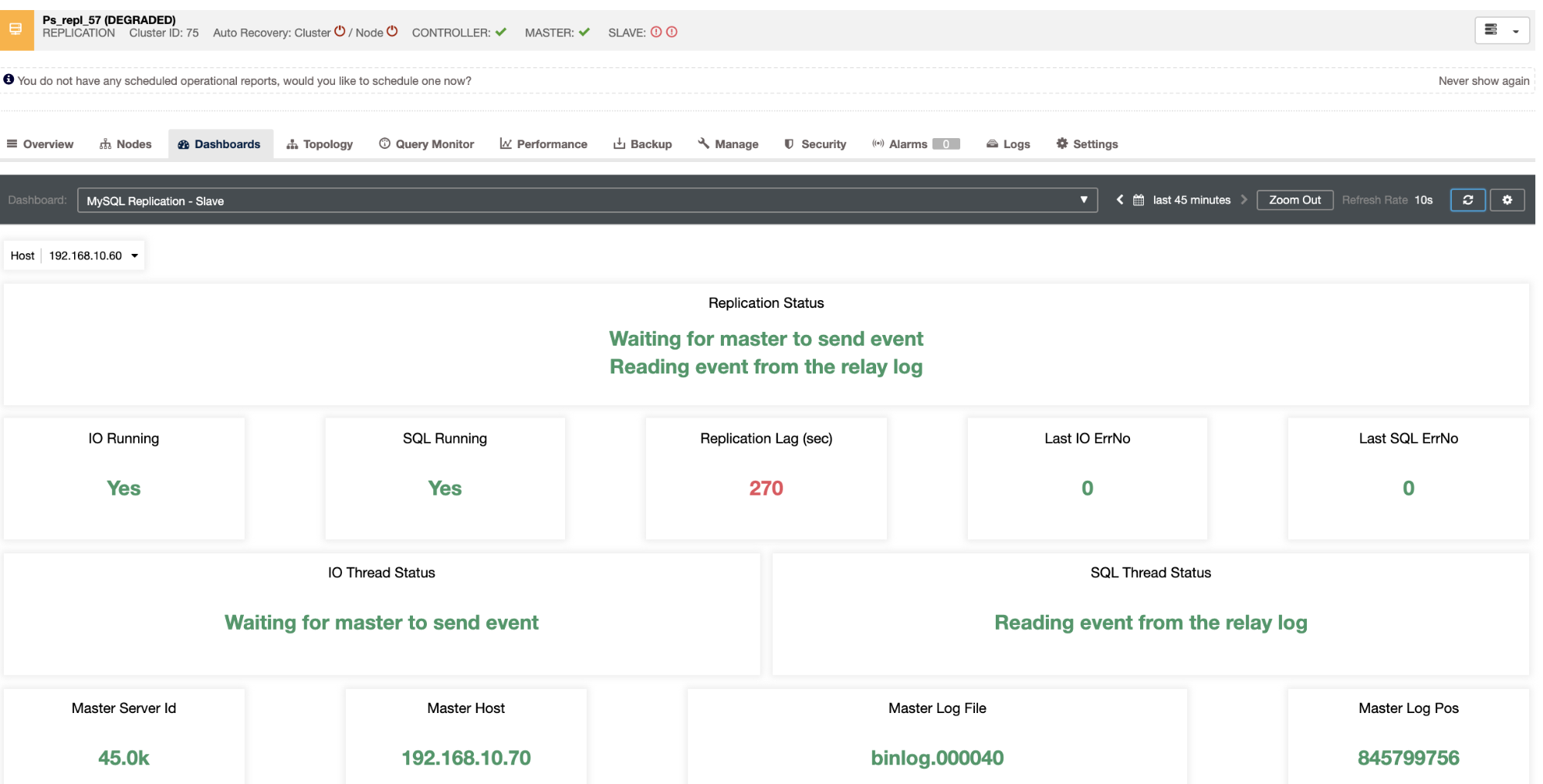
With many different databases, companies are now overwhelmed with choices, allowing them to have a combination of database types to support the various applications they have in their environment. The combination usually depends on the interaction and data support between the database and the applications. To maintain these multi environments, companies should be prepared to invest in either a multi-skilled DBA or have a good open source database management system (like ClusterControl) to deploy, manage, and monitor the various databases in their environment.
The Leading Open Source Databases
The survey on open source databases also highlighted the top databases installed in 2019, and the five leading databases are as below
Postgres-XL, Clustrix, Alibaba Cloud: ApsaraDB RDS for PostgreSQL, FoundationDB Document Layer and Azure Cosmos DB are at the bottom 5 with less than 1% installation for the year.
MySQL - Variants and Combinations
The MySQL Community Edition secured the title for most deployed database for the year of 2019. The top five most popular MySQL-compatible softwares after the community version are...
- MariaDB Community
- Percona Server for MySQL
- MySQL on Amazon RDS
- Percona XtraDB Cluster
- Amazon Aurora
MySQL combinations with other databases differ based on the editions. PostgreSQL, Elastic, Redis and MongoDB commonly used with the MySQL Community version. On the other hand, with the Enterprise Version, proprietary databases, SQL Server and Oracle are used as the best combination.
64% of the community also selected PostgreSQL as a popular database to use alongside the enterprise edition. These results show clearly that the community version is not usually paired with a proprietary database. It is assumed that there could be two main reasons for this decision; lack of skills to manage multiple open source databases and/or the fact that management has concerns over the support of stability of the open source products.
PostgreSQL - Variants and Combinations
PostgreSQL has gained a lot of attention in the last few years and has the most installation after the MySQL database. Its strength lies in the large community base which contributes to its upgrades and expansions. Although there are many compatible versions, only the standard version is preferred one. PostgreSQL is coupled most with Elastic, MongoDB, SQL, and Redis. The enterprise version, like MySQL Enterprise, is commonly paired with the enterprise databases like Oracle and SQL Server.
MongoDB - Variants and Combinations
MongoDB gained its popularity along with big data and its ability to overcome the limitation of a rigid relational database with NoSQL. NoSQL paved the way for agile development and supports flexibility and scalability. Like the other two, MongoDB Community is still the most widely used version by small and medium companies, and the enterprise version is only used by large organisations.
Open Source Database Adoption
Open-source databases gained popularity because of cost-saving and to avoid vendor lock-in situations. Another bit of good news is that these databases work for any business size, hence it is widely used by small, medium, and large companies alike.
Open source tools give a platform for experimentation, which allows the users to use a community edition, and get comfortable with it, before moving on to further deployments. On average 53% of companies are moving into the open-source software adoption.

Open Source Community Contributions
Enhancement in the open source world really depends on the contributions from its user community. This is why open source software with a large community (like PostgreSQL) is always adopted widely by small, medium, and large companies. Although companies are geared up for open source adoption, and do know the need to contribute, many of the users have said they don't have the time to contribute back to the libraries.
Support Services
The next main concern on the adoption of open source is around support preferences. Generally, small scale companies management and technical staff prefer a self-support option.
Support services are also a limiting factor. Companies are often worried about the support mechanism, especially during times of crisis. They lack confidence in their own support team or it could be the internal team just has too many other tasks, making it impossible to give adequate support.
Small companies usually rely on self-support to minimize cost. To increase confidence in the open source solution, some companies appoint external vendors for support services. Another option which can be considered is to opt for an open source database management system which includes support services as well.
Enterprise or Subscribed Database Preferences
There is still a large percentage of companies using proprietary databases for three major reasons; the strong 24x7 dedicated support line, brand trust, and the enhanced security. Trust is tagged with a long established brand which gives peace of mind to the users. Despite these factors, community open source still wins with one major factor which is cost saving.
Open Source Database Adoption Concerns
The survey showed there are three main adoption concerns (besides vendor lock-in).
The first concern is the lack of support which has been discussed in the earlier sections of this blog. Next is the concern around the lack of fixes and bugs from the small and medium companies. The worry could be on the cost incurred to fix any bugs.
Large companies are not worried about this, because they can afford the cost to hire someone to fix any bugs and even further enhance the system.
Security is the third reason, and this concern is mainly from the technical team because they are responsible for the security compliance of its systems in the organisation.
Conclusion
Adopting an open source database is the way-to-go for any size business and is the best fit if cost and avoiding vendor lock-in is a concern. You also need to be aware of, and check on, the support mechanism, patch support, and security aspects before making a choice.
Along with the open source technology adoption, you would need a proper technical team to manage the database and have a proper support mechanism to handle any limitations.
Open source technologies allow you to experiment with the available free or community versions and then decide to go ahead with the licensed or enterprise version if required.
The great thing is that with open source technologies, you won't have to settle for one database anymore, as you have more than one to serve the different aspects of your business.