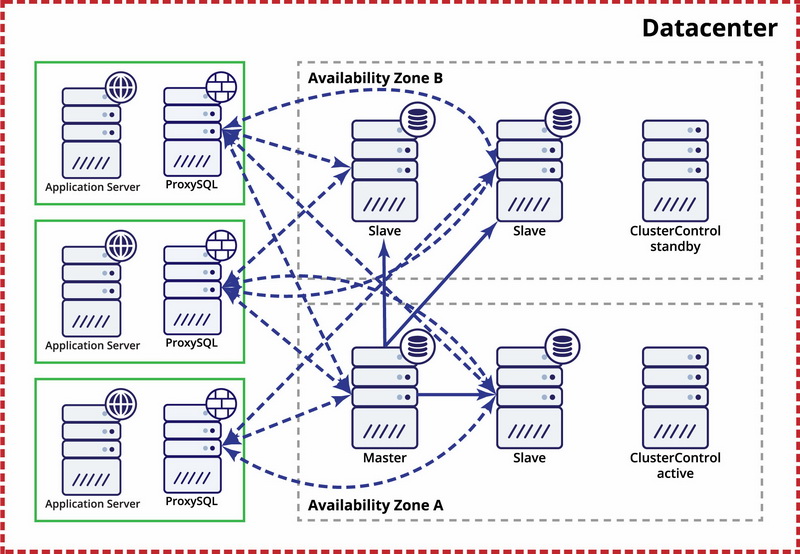
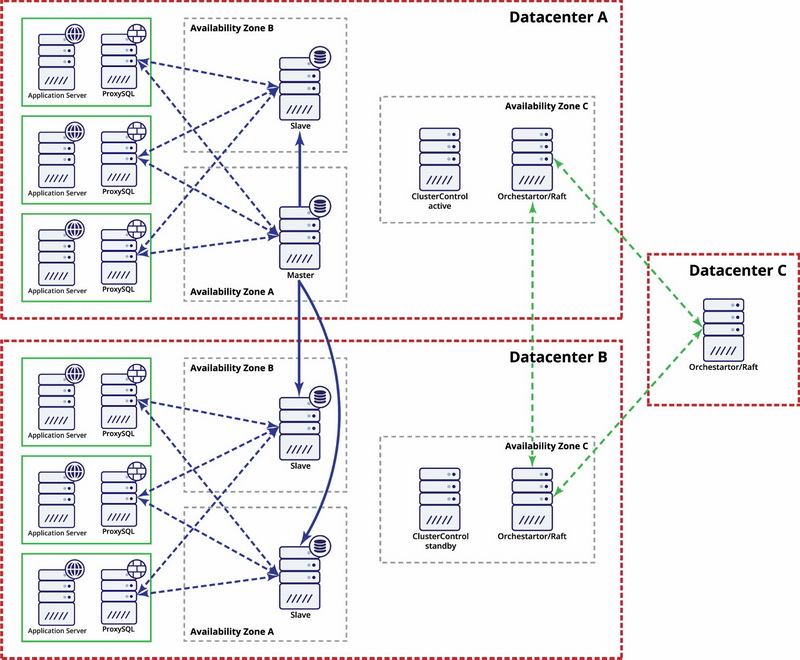
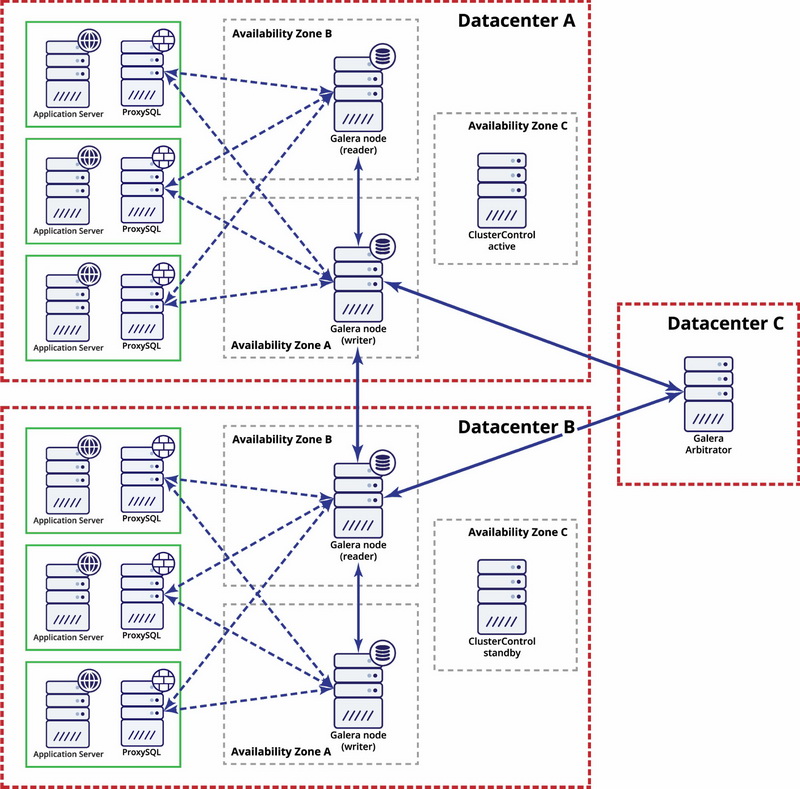
ClusterControl can be used to deploy highly available replication setups. It supports switchover and failover for GTID-based MySQL or MariaDB replication setups. ClusterControl can deploy different types of proxies for traffic routing: ProxySQL, HAProxy and MaxScale. These are integrated to handle topology changes related to failovers or switchovers. In this blog post, we’ll take a look at how this works and what you can expect from each of the proxies.
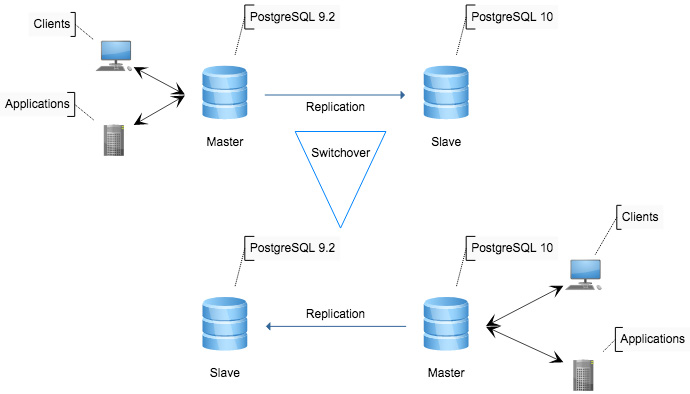
First, let’s go through some definitions and terminology. ClusterControl can be configured to perform a recovery of a failed replication master - it can promote a slave to become the new master, make any required topology changes and restore entire setup’s ability to accept writes. This is what we will call a “failover”. ClusterControl can also perform a master switch - sometimes it’s required to change a master. Typical scenario would be a heavy schema change, which has to be executed in a rolling fashion. Towards the end of the procedure, you’ll have to promote one of the slaves, which already has the change applied, before performing the change on the old master.
The main difference between “failover” and “switchover” is that failover, by definition, is an emergency situation where the master is already unavailable. On the other hand, switchover is a more controllable process over which ClusterControl has full control. If we are talking about failover, there is no way to handle it gracefully as application already lost connections due to master crash. As such, no matter which proxy you will use, application will always have to reconnect.
So, applications need to be able to handle transaction failures and retry them. The other important thing when speaking about failover is the proxy’s ability to check the health of the database servers. Without health checks, the proxy cannot know the status of the server, and therefore cannot decide to failover traffic. ClusterControl automatically configures these healthchecks when deploying the proxy.
Failover
ProxySQL
Let’s take a look at how the failover may look like from the application point of view. We will first connect to the database using ProxySQL version 1.4.6.
root@vagrant:~# while true ;do time sysbench /root/sysbench/src/lua/oltp_read_write.lua --threads=4 --max-requests=0 --time=3600 --mysql-host=10.0.0.105 --mysql-user=sbtest --mysql-password=pass --mysql-port=6033 --tables=32 --report-interval=1 --skip-trx=on --table-size=10000 --db-ps-mode=disable run ; done
sysbench 1.1.0-651e7fd (using bundled LuaJIT 2.1.0-beta3)
Running the test with following options:
Number of threads: 4
Report intermediate results every 1 second(s)
Initializing random number generator from current time
Initializing worker threads...
Threads started!
[ 1s ] thds: 4 tps: 29.51 qps: 585.28 (r/w/o: 465.27/120.01/0.00) lat (ms,95%): 196.89 err/s: 0.00 reconn/s: 0.00
[ 2s ] thds: 4 tps: 44.61 qps: 784.77 (r/w/o: 603.28/181.49/0.00) lat (ms,95%): 116.80 err/s: 0.00 reconn/s: 0.00
[ 3s ] thds: 4 tps: 46.98 qps: 829.66 (r/w/o: 646.74/182.93/0.00) lat (ms,95%): 121.08 err/s: 0.00 reconn/s: 0.00
[ 4s ] thds: 4 tps: 49.04 qps: 886.64 (r/w/o: 690.50/195.14/1.00) lat (ms,95%): 112.67 err/s: 0.00 reconn/s: 0.00
[ 5s ] thds: 4 tps: 47.98 qps: 887.64 (r/w/o: 689.72/197.92/0.00) lat (ms,95%): 106.75 err/s: 0.00 reconn/s: 0.00
FATAL: mysql_drv_query() returned error 2013 (Lost connection to MySQL server during query) for query 'UPDATE sbtest8 SET k=k+1 WHERE id=5019'
FATAL: `thread_run' function failed: /usr/local/share/sysbench/oltp_common.lua:461: SQL error, errno = 2013, state = 'HY000': Lost connection to MySQL server during query
FATAL: mysql_drv_query() returned error 2013 (Lost connection to MySQL server during query) for query 'DELETE FROM sbtest6 WHERE id=4957'
FATAL: `thread_run' function failed: /usr/local/share/sysbench/oltp_common.lua:490: SQL error, errno = 2013, state = 'HY000': Lost connection to MySQL server during query
FATAL: mysql_drv_query() returned error 2013 (Lost connection to MySQL server during query) for query 'SELECT SUM(k) FROM sbtest23 WHERE id BETWEEN 4986 AND 5085'
FATAL: `thread_run' function failed: /usr/local/share/sysbench/oltp_common.lua:435: SQL error, errno = 2013, state = 'HY000': Lost connection to MySQL server during query
FATAL: mysql_drv_query() returned error 2013 (Lost connection to MySQL server during query) for query 'DELETE FROM sbtest21 WHERE id=5218'
FATAL: `thread_run' function failed: /usr/local/share/sysbench/oltp_common.lua:490: SQL error, errno = 2013, state = 'HY000': Lost connection to MySQL server during query
real 0m5.903s
user 0m0.092s
sys 0m1.252s
sysbench 1.1.0-651e7fd (using bundled LuaJIT 2.1.0-beta3)
Running the test with following options:
Number of threads: 4
Report intermediate results every 1 second(s)
Initializing random number generator from current time
Initializing worker threads...
FATAL: unable to connect to MySQL server on host '10.0.0.105', port 6033, aborting...
FATAL: error 2003: Can't connect to MySQL server on '10.0.0.105' (111)
FATAL: `thread_init' function failed: /usr/local/share/sysbench/oltp_common.lua:352: connection creation failed
FATAL: unable to connect to MySQL server on host '10.0.0.105', port 6033, aborting...
FATAL: error 2003: Can't connect to MySQL server on '10.0.0.105' (111)
FATAL: `thread_init' function failed: /usr/local/share/sysbench/oltp_common.lua:352: connection creation failed
FATAL: unable to connect to MySQL server on host '10.0.0.105', port 6033, aborting...
FATAL: error 2003: Can't connect to MySQL server on '10.0.0.105' (111)
FATAL: `thread_init' function failed: /usr/local/share/sysbench/oltp_common.lua:352: connection creation failed
FATAL: unable to connect to MySQL server on host '10.0.0.105', port 6033, aborting...
FATAL: error 2003: Can't connect to MySQL server on '10.0.0.105' (111)
FATAL: `thread_init' function failed: /usr/local/share/sysbench/oltp_common.lua:352: connection creation failed
FATAL: Threads initialization failed!
real 0m0.021s
user 0m0.012s
sys 0m0.000s
sysbench 1.1.0-651e7fd (using bundled LuaJIT 2.1.0-beta3)
Running the test with following options:
Number of threads: 4
Report intermediate results every 1 second(s)
Initializing random number generator from current time
Initializing worker threads...
Threads started!
[ 1s ] thds: 4 tps: 0.00 qps: 55.81 (r/w/o: 55.81/0.00/0.00) lat (ms,95%): 0.00 err/s: 0.00 reconn/s: 0.00
[ 2s ] thds: 4 tps: 0.00 qps: 0.00 (r/w/o: 0.00/0.00/0.00) lat (ms,95%): 0.00 err/s: 0.00 reconn/s: 0.00
[ 3s ] thds: 4 tps: 0.00 qps: 0.00 (r/w/o: 0.00/0.00/0.00) lat (ms,95%): 0.00 err/s: 0.00 reconn/s: 0.00
[ 4s ] thds: 4 tps: 0.00 qps: 0.00 (r/w/o: 0.00/0.00/0.00) lat (ms,95%): 0.00 err/s: 0.00 reconn/s: 0.00
[ 5s ] thds: 4 tps: 0.00 qps: 0.00 (r/w/o: 0.00/0.00/0.00) lat (ms,95%): 0.00 err/s: 0.00 reconn/s: 0.00
[ 6s ] thds: 4 tps: 0.00 qps: 0.00 (r/w/o: 0.00/0.00/0.00) lat (ms,95%): 0.00 err/s: 0.00 reconn/s: 0.00
[ 7s ] thds: 4 tps: 0.00 qps: 0.00 (r/w/o: 0.00/0.00/0.00) lat (ms,95%): 0.00 err/s: 0.00 reconn/s: 0.00
[ 8s ] thds: 4 tps: 0.00 qps: 0.00 (r/w/o: 0.00/0.00/0.00) lat (ms,95%): 0.00 err/s: 0.00 reconn/s: 0.00
[ 9s ] thds: 4 tps: 0.00 qps: 0.00 (r/w/o: 0.00/0.00/0.00) lat (ms,95%): 0.00 err/s: 0.00 reconn/s: 0.00
[ 10s ] thds: 4 tps: 0.00 qps: 3.00 (r/w/o: 0.00/3.00/0.00) lat (ms,95%): 0.00 err/s: 0.00 reconn/s: 0.00
[ 11s ] thds: 4 tps: 58.99 qps: 1026.91 (r/w/o: 792.93/233.98/0.00) lat (ms,95%): 9977.52 err/s: 0.00 reconn/s: 0.00As we can see from the above, the new master became available within ~11 seconds of the crash. During this time, ClusterControl promoted one of the slaves to become a new master and it became available for writes.
HAProxy
Below is an excerpt from the output of our sysbench application, when failover happened while we connected via HAProxy. HAProxy was deployed with version 1.5.14.
root@vagrant:~# while true ;do date ; time sysbench /root/sysbench/src/lua/oltp_read_write.lua --threads=4 --max-requests=0 --time=3600 --mysql-host=10.0.0.105 --mysql-user=sbtest --mysql-password=pass --mysql-port=3307 --tables=32 --report-interval=1 --skip-trx=on --table-size=10000 --db-ps-mode=disable run ; done
Mon Mar 26 13:24:36 UTC 2018
sysbench 1.1.0-651e7fd (using bundled LuaJIT 2.1.0-beta3)
Running the test with following options:
Number of threads: 4
Report intermediate results every 1 second(s)
Initializing random number generator from current time
Initializing worker threads...
Threads started!
[ 1s ] thds: 4 tps: 38.62 qps: 748.66 (r/w/o: 591.21/157.46/0.00) lat (ms,95%): 204.11 err/s: 0.00 reconn/s: 0.00
[ 2s ] thds: 4 tps: 45.25 qps: 797.34 (r/w/o: 619.37/177.97/0.00) lat (ms,95%): 142.39 err/s: 0.00 reconn/s: 0.00
[ 3s ] thds: 4 tps: 46.04 qps: 833.66 (r/w/o: 647.51/186.15/0.00) lat (ms,95%): 155.80 err/s: 0.00 reconn/s: 0.00
[ 4s ] thds: 4 tps: 38.03 qps: 698.50 (r/w/o: 548.39/150.11/0.00) lat (ms,95%): 161.51 err/s: 0.00 reconn/s: 0.00
FATAL: mysql_drv_query() returned error 2013 (Lost connection to MySQL server during query) for query 'INSERT INTO sbtest26 (id, k, c, pad) VALUES (5019, 4641, '59053342586-08172779908-92479743240-43242105725-10632773383-95161136797-93281862044-04686210438-11173993922-29424780352', '31974441818-04649488782-29232641118-20479872868-43849012112')'
FATAL: `thread_run' function failed: /usr/local/share/sysbench/oltp_common.lua:491: SQL error, errno = 2013, state = 'HY000': Lost connection to MySQL server during query
FATAL: mysql_drv_query() returned error 2013 (Lost connection to MySQL server during query) for query 'INSERT INTO sbtest5 (id, k, c, pad) VALUES (4990, 5016, '24532768797-67997552950-32933774735-28931955363-94029987812-56997738696-36504817596-46223378508-29593036153-06914757723', '96663311222-58437606902-85941187037-63300736065-65139798452')'
FATAL: `thread_run' function failed: /usr/local/share/sysbench/oltp_common.lua:491: SQL error, errno = 2013, state = 'HY000': Lost connection to MySQL server during query
FATAL: mysql_drv_query() returned error 2013 (Lost connection to MySQL server during query) for query 'DELETE FROM sbtest25 WHERE id=4996'
FATAL: `thread_run' function failed: /usr/local/share/sysbench/oltp_common.lua:490: SQL error, errno = 2013, state = 'HY000': Lost connection to MySQL server during query
FATAL: mysql_drv_query() returned error 2013 (Lost connection to MySQL server during query) for query 'UPDATE sbtest16 SET k=k+1 WHERE id=5269'
FATAL: `thread_run' function failed: /usr/local/share/sysbench/oltp_common.lua:461: SQL error, errno = 2013, state = 'HY000': Lost connection to MySQL server during query
real 0m4.270s
user 0m0.068s
sys 0m0.928s
...
Mon Mar 26 13:24:47 UTC 2018
sysbench 1.1.0-651e7fd (using bundled LuaJIT 2.1.0-beta3)
Running the test with following options:
Number of threads: 4
Report intermediate results every 1 second(s)
Initializing random number generator from current time
Initializing worker threads...
FATAL: unable to connect to MySQL server on host '10.0.0.105', port 3307, aborting...
FATAL: error 2013: Lost connection to MySQL server at 'reading initial communication packet', system error: 0
FATAL: `thread_init' function failed: /usr/local/share/sysbench/oltp_common.lua:352: connection creation failed
FATAL: unable to connect to MySQL server on host '10.0.0.105', port 3307, aborting...
FATAL: error 2013: Lost connection to MySQL server at 'reading initial communication packet', system error: 2
FATAL: `thread_init' function failed: /usr/local/share/sysbench/oltp_common.lua:352: connection creation failed
FATAL: unable to connect to MySQL server on host '10.0.0.105', port 3307, aborting...
FATAL: error 2013: Lost connection to MySQL server at 'reading initial communication packet', system error: 2
FATAL: `thread_init' function failed: /usr/local/share/sysbench/oltp_common.lua:352: connection creation failed
FATAL: unable to connect to MySQL server on host '10.0.0.105', port 3307, aborting...
FATAL: error 2013: Lost connection to MySQL server at 'reading initial communication packet', system error: 2
FATAL: `thread_init' function failed: /usr/local/share/sysbench/oltp_common.lua:352: connection creation failed
FATAL: Threads initialization failed!
real 0m0.036s
user 0m0.004s
sys 0m0.008s
...
Mon Mar 26 13:25:03 UTC 2018
sysbench 1.1.0-651e7fd (using bundled LuaJIT 2.1.0-beta3)
Running the test with following options:
Number of threads: 4
Report intermediate results every 1 second(s)
Initializing random number generator from current time
Initializing worker threads...
Threads started!
[ 1s ] thds: 4 tps: 50.58 qps: 917.42 (r/w/o: 715.10/202.33/0.00) lat (ms,95%): 153.02 err/s: 0.00 reconn/s: 0.00
[ 2s ] thds: 4 tps: 50.17 qps: 956.33 (r/w/o: 749.61/205.72/1.00) lat (ms,95%): 121.08 err/s: 0.00 reconn/s: 0.00In total, the process took 12 seconds.
MaxScale
Let’s take a look at how MaxScale handles failover. We use MaxScale with version 2.1.9.
root@vagrant:~# while true ; do date ; time sysbench /root/sysbench/src/lua/oltp_read_write.lua --threads=4 --max-requests=0 --time=3600 --mysql-host=10.0.0.106 --mysql-user=myuser --mysql-password=pass --mysql-port=4008 --tables=32 --report-interval=1 --skip-trx=on --table-size=100000 --db-ps-mode=disable run ; done
Mon Mar 26 15:16:34 UTC 2018
sysbench 1.1.0-651e7fd (using bundled LuaJIT 2.1.0-beta3)
Running the test with following options:
Number of threads: 4
Report intermediate results every 1 second(s)
Initializing random number generator from current time
Initializing worker threads...
Threads started!
[ 1s ] thds: 4 tps: 34.82 qps: 658.54 (r/w/o: 519.27/125.34/13.93) lat (ms,95%): 137.35 err/s: 0.00 reconn/s: 0.00
[ 2s ] thds: 4 tps: 35.01 qps: 655.23 (r/w/o: 513.18/142.05/0.00) lat (ms,95%): 207.82 err/s: 0.00 reconn/s: 0.00
[ 3s ] thds: 4 tps: 39.01 qps: 696.16 (r/w/o: 542.13/154.04/0.00) lat (ms,95%): 139.85 err/s: 0.00 reconn/s: 0.00
[ 4s ] thds: 4 tps: 40.91 qps: 724.41 (r/w/o: 557.77/166.63/0.00) lat (ms,95%): 125.52 err/s: 0.00 reconn/s: 0.00
FATAL: mysql_drv_query() returned error 1053 (Server shutdown in progress) for query 'UPDATE sbtest28 SET k=k+1 WHERE id=49992'
FATAL: `thread_run' function failed: /usr/local/share/sysbench/oltp_common.lua:461: SQL error, errno = 1053, state = '08S01': Server shutdown in progress
FATAL: mysql_drv_query() returned error 1053 (Server shutdown in progress) for query 'UPDATE sbtest14 SET k=k+1 WHERE id=59650'
FATAL: `thread_run' function failed: /usr/local/share/sysbench/oltp_common.lua:461: SQL error, errno = 1053, state = '08S01': Server shutdown in progress
FATAL: mysql_drv_query() returned error 1053 (Server shutdown in progress) for query 'UPDATE sbtest12 SET k=k+1 WHERE id=50288'
FATAL: `thread_run' function failed: /usr/local/share/sysbench/oltp_common.lua:461: SQL error, errno = 1053, state = '08S01': Server shutdown in progress
FATAL: mysql_drv_query() returned error 1053 (Server shutdown in progress) for query 'UPDATE sbtest25 SET k=k+1 WHERE id=50105'
FATAL: `thread_run' function failed: /usr/local/share/sysbench/oltp_common.lua:461: SQL error, errno = 1053, state = '08S01': Server shutdown in progress
real 0m5.043s
user 0m0.080s
sys 0m1.044s
Mon Mar 26 15:16:53 UTC 2018
sysbench 1.1.0-651e7fd (using bundled LuaJIT 2.1.0-beta3)
Running the test with following options:
Number of threads: 4
Report intermediate results every 1 second(s)
Initializing random number generator from current time
Initializing worker threads...
Threads started!
[ 1s ] thds: 4 tps: 46.82 qps: 905.61 (r/w/o: 710.34/195.27/0.00) lat (ms,95%): 101.13 err/s: 0.00 reconn/s: 0.00Failover summary
It is important to clarify that this is not a scientific benchmark - most of the time is used by ClusterControl to perform the failover. Proxies typically need a couple of seconds at most to detect the topology change. We used sysbench as our application. It was configured to run auto-committed transactions, so neither explicit transactions nor prepared statements have been used. Sysbench’s read/write workload is pretty fast. If you have long-running transactions or queries, the failover performance will differ. You can see our scenario as a best case.
Switchover
As we mentioned earlier, when executing a switchover ClusterControl has more control of the master. Under some circumstances (like no transactions, no long running writes, etc.), it may be able to perform a graceful master switch, as long as the proxy supports this. Unfortunately, as of now, none of the proxies deployable by ClusterControl can handle graceful switchover. In the past, ProxySQL had this capability therefore we decided to investigate closer and got in touch with ProxySQL creator, René Cannaò. During the investigation we identified a regression which should be fixed in the next release of ProxySQL. In the meantime, to showcase how ProxySQL should behave, we used ProxySQL patched with a small workaround which we compiled from source.
[ 16s ] thds: 4 tps: 39.01 qps: 711.11 (r/w/o: 555.09/156.02/0.00) lat (ms,95%): 173.58 err/s: 0.00 reconn/s: 0.00
[ 17s ] thds: 4 tps: 49.00 qps: 879.06 (r/w/o: 678.05/201.01/0.00) lat (ms,95%): 102.97 err/s: 0.00 reconn/s: 0.00
[ 18s ] thds: 4 tps: 42.86 qps: 768.57 (r/w/o: 603.09/165.48/0.00) lat (ms,95%): 176.73 err/s: 0.00 reconn/s: 0.00
[ 19s ] thds: 4 tps: 28.07 qps: 521.26 (r/w/o: 406.98/114.28/0.00) lat (ms,95%): 235.74 err/s: 0.00 reconn/s: 0.00
[ 20s ] thds: 4 tps: 0.00 qps: 0.00 (r/w/o: 0.00/0.00/0.00) lat (ms,95%): 0.00 err/s: 0.00 reconn/s: 0.00
[ 21s ] thds: 4 tps: 0.00 qps: 0.00 (r/w/o: 0.00/0.00/0.00) lat (ms,95%): 0.00 err/s: 0.00 reconn/s: 0.00
[ 22s ] thds: 4 tps: 0.00 qps: 0.00 (r/w/o: 0.00/0.00/0.00) lat (ms,95%): 0.00 err/s: 0.00 reconn/s: 0.00
[ 23s ] thds: 4 tps: 13.98 qps: 249.59 (r/w/o: 193.68/55.91/0.00) lat (ms,95%): 4055.23 err/s: 0.00 reconn/s: 0.00
[ 24s ] thds: 4 tps: 81.06 qps: 1449.01 (r/w/o: 1123.79/325.23/0.00) lat (ms,95%): 62.19 err/s: 0.00 reconn/s: 0.00
[ 25s ] thds: 4 tps: 52.02 qps: 923.42 (r/w/o: 715.32/208.09/0.00) lat (ms,95%): 390.30 err/s: 0.00 reconn/s: 0.00
[ 26s ] thds: 4 tps: 59.00 qps: 1082.94 (r/w/o: 844.96/237.99/0.00) lat (ms,95%): 164.45 err/s: 0.00 reconn/s: 0.00
[ 27s ] thds: 4 tps: 50.99 qps: 900.75 (r/w/o: 700.81/199.95/0.00) lat (ms,95%): 130.13 err/s: 0.00 reconn/s: 0.00As you can see, no queries are executed for 4 seconds but no error is returned to the application and after this pause, the traffic starts to flow once more.
To summarize, we have shown that ClusterControl, when used with ProxySQL or MaxScale or HAProxy, can perform a failover with a downtime of 10 - 15 seconds. With respect to a planned master switch, none of the proxies can handle the procedure without errors at the time of writing. However, it is expected that the next ProxySQL version will allow a switchover of a few seconds without any error showing up in the application.